30
Obdelava naravnega jezika je tema številnih raziskav že zadnjih 50 let. Nekatera izmed raziskovalnih prizadevanj na tem področju so privedla do razvoja orodij, ki jih uporabljamo vsak dan:
- urejevalniki besedil,
- samodejni predlogi za slovnične in pravopisne popravke,
- samodejno zapolnjevanje podatkov,
- optično prepoznavanje znakov (OCR).
V zadnjem času imajo na vseh področjih življenja velik vpliv predvsem klepetalni roboti, pametni/hišni/osebni asistenti in prevajalniki.
Dolgo časa je raziskave in industrijo na tem področju upočasnjevala imanentna kompleksnost jezika. Ob koncu 20. stoletja so slovnice (rezultat dela področnih strokovnjakov) različnih jezikov vsebovale tudi do 50.000 pravil. Takšni ekspertni sistemi so nakazovali možnost izboljšav s pomočjo tehnologije, vendar so bile zanesljive (univerzalne) rešitve prezapletene za razvoj.
Po drugi strani je tehnologija prepoznavanja govora zahtevala obdelavo akustičnih podatkov in njihovo pretvorbo v besedilo. Ob vsej raznolikosti govorcev je bil to zares trd oreh.
Raziskovalci so dojeli, da bo to lažje izvedljivo s pomočjo modela jezika. Če model pozna besedišče izbranega jezika in pravila za tvorjenje stavkov, bo iz serije predlogov lažje izbral tisti pravi stavek, ki bo ustrezal zapisanemu/izrečenemu, oz., lažje bo izbral prevodno ustreznico izmed niza možnih zaporedij besed.
Drug ključni vidik pri tem je semantika (pomenoslovje). Največ, kar lahko tehnologija stori pri reševanju jezikovnih vprašanj, je pravzaprav površinske narave: algoritem predlaga odgovor na podlagi določenih skladenjskih pravil. Nič zato, če na koncu besedilo nima nobenega smisla. Podobno bi se lahko zgodilo pri branju besedil učencev – če bi samo popravljali napake, ne da bi zares razumeli, o čem besedilo govori. Bistvo je v seveda v pomenu, ki ga pripišemo besedilom oz. izrečenim besedam.
Leta 2008 je prišlo do preboja1: ustvarjen je bil edinstven jezikovni model, ki se je učil iz velikanske količine podatkov in ga je postalo mogoče uporabiti za različne jezikovne naloge. Dejansko je deloval bolje kot modeli, ki so bili naučeni izvajati posamezne od teh nalog.
Ta model je bil globoka nevronska mreža. Čeprav ni bila niti približno tako globoka kot mreže, ki se uporabljajo danes, so bili rezultati dovolj prepričljivi, da so raziskovalci pričeli verjeti, da bo strojno učenje, natančneje globoko učenje, odgovor na številna vprašanja glede NLP.
Od takrat tehnologije NLP niso več sledile pristopu na osnovi modelov, temveč se je uveljavil pristop, ki temelji na podatkih.
Jezikovne naloge v tem smislu razdelimo na dva sklopa: tiste, ki vključujejo ustvarjanje modelov, in tiste, ki vključujejo dekodiranje.
Ustvarjanje modelov
Če želite prepis (transkripcijo), odgovor na vprašanje, dialog ali prevod, morate najprej vedeti, ali je npr. stavek “Je parle Français” res legitimen stavek v francoščini ali ne. In ker pri govorjenem jeziku slovnična pravila niso vedno natančno upoštevana, bo odgovor izražen z verjetnostjo: stavek je bolj ali manj francoski. Na podlagi tega tudi sistem pripravi različne predloge stavkov (transkripcijo slišanega, prevod stavka itd.), in verjetnost ustreznosti tudi razvrsti (oceni). Uporabnik nato lahko izbere stavek z najvišjo oceno (tj. z najvišjo verjetnostjo ustreznosti) ali pa to informacijo kombinira z drugimi viri informacij (pomen stavka).
Prav to počnejo jezikovni modeli: verjetnosti izračunajo na podlagi algoritmov strojnega učenja. In seveda, čim več podatkov je na voljo, tem bolje. Za nekatere jezike je na voljo veliko podatkov, na podlagi katerih lahko ustvarimo jezikovne modele, pri drugih jezikih pa ni tako.
Za nalogo prevajanja nista potrebna dva, temveč trije modeli: jezikovni model za vsakega izmed obeh jezikov in še en model za prevode, ki nam pove, kateri prevodi fragmentov jezika so boljši oz., ustreznejši. Takšne modele je težko izdelati, če je podatkov malo. Medtem, ko je modele za pogoste “jezikovne pare” lažje izdelati, to ne velja za jezike, ki se ne uporabljajo pogosto “v paru” (npr., portugalščina in slovenščina). Tipična rešitev pri tem je uporaba/prevajanje preko vmesnega jezika (običajno angleščine): iz portugalščine v angleščino in nato iz angleščine v slovenščino. To seveda vodi do manj ustreznih rezultatov, saj se napake kopičijo.
Dekodiranje
Dekodiranje je proces, pri katerem algoritem sprejme vhodno zaporedje (v obliki signala ali besedila) in na podlagi informacij, ki jih vsebuje model, sprejme odločitev, pogosto v obliki izhodnega besedila. Pri tem je treba upoštevati določene zakonitostmi algoritmov: transkripcija in prevajanje morata običajno potekati v realnem času, zato je pri tem ključno vprašanje zmanjševanje časovnega zaostanka. Prostora za delovanje UI je tu veliko.
Celovit pristop
Procese ločenega ustvarjanja in kasneje kombiniranja teh komponent je danes nadomestil celovit pristop, pri katerem sistem zapiše/prevede/interpretira vhodne podatke s pomočjo edinstvenega modela. Trenutno se taki modeli učijo s pomočjo izjemno zapletenih globokih nevronskih mrež: največji model GPT3 naj bi obsegal več sto milijonov parametrov.
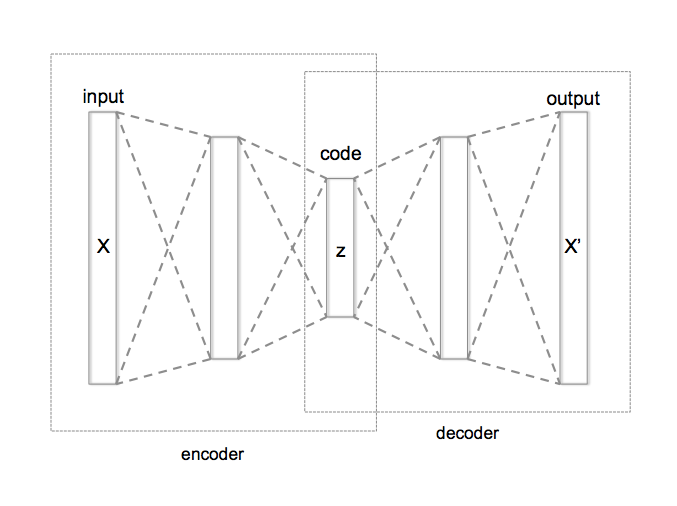
Poskusimo poenostaviti: predpostavimo, da imamo določene podatke. Te surove podatke lahko na poljuben način zakodiramo. Toda kodiranje je lahko redundantno in morda celo zelo drago. Zato izdelamo posebno napravo, samodejni kodirnik (slika desno). Stroj prvotno besedilo prenese v majhen vektor (kodirnik), nato pa vektor razširi (dekodirnik) in ponovno vzpostavi besedilo, ki je nekako blizu prvotnemu besedilu. Ideja je v tem, da ta mehanizem ustvari zelo koristen vmesni vektor – zaradi dveh zaželenih lastnosti: je majhen, in “vsebuje” informacije o prvotnem besedilu.
Prihodnost
Verjetno bodo takšni celoviti pristopi kmalu omogočali, da bo vmesnik (1) slišal in prepoznal, kateri jezik govorite, (2) zapisal izgovorjeno besedilo, (3) ga prevedel v jezik, ki ga ne poznate, (4) usposobil sistem za sintezo govora za prepoznavanje vašega glasu in (5) z vašim glasom prebral ustrezno prevedeno besedilo v drugem jeziku. Na posnetkih spodaj si oglejte dva primera, ki so ju zasnovali raziskovalci na Universidad Politecnica de Valencia v Španiji, v katerih je za sinhronizacijo uporabljen model lastnega glasu govorca.
Vpliv na izobraževanje
Stalen napredek obdelave naravnega jezika je izjemen. Če smo se še samo deset let nazaj smejali neumnim prevodom, ki jih je predlagala UI, danes pri tem vse težje najdemo grobe napake. Hitro se izboljšujejo tudi tehnike prepoznavanja govora in znakov.
Semantični izzivi so še vedno prisotni in odgovarjanje UI na vprašanja, ki zahtevajo poglobljeno razumevanje besedila, še vedno ne deluje pravilno. Vendar gredo stvari v pravo smer. To pomeni, da morajo učitelji pričakovati, da bodo nekatere od naslednjih trditev kmalu postale resnične, če že niso.
- Učenec vzame zahtevno besedilo in (s pomočjo UI) generira poenostavljeno različico; besedilo bo lahko celo povsem prilagojeno in bodo v njem uporabljeni izrazi, besede in pojmi, ki bi jih pričakovali od dotičnega učenca;
- učenec bo lahko na podlagi danega besedila generiral drugačno besedilo, ki bo govorilo o isti temi, vendar ga orodje za preprečevanje plagiatorstva ne bo zaznalo kot plagiat;
- videoposnetki v kateremkoli jeziku bodo dostopni s samodejno sinhronizacijo v kateremkoli drugem jeziku: to pomeni, da učenci ne bodo izpostavljeni le učnemu gradivu, zasnovanem in izdelanem v njihovem maternem jeziku, temveč tudi gradivu, ki je bilo prvotno zasnovano za drug učni sistem, za drugo kulturo;
- pisanje esejev bi lahko postalo stvar preteklosti, saj bodo orodja UI omogočala pisanje sestavkov na katerokoli temo.
Jasno je, da UI pri teh opravilih vsaj na začetku še zdaleč ne bo popolna in da bo strokovnjak vedno odkril, da četudi je raba jezika pravilna, tok misli morda ni (koherenten). Toda povejmo pošteno: koliko časa pa za to v celotnem procesu izobraževanja potrebujejo naši dijaki in študenti?
1 Collobert, Ronan, and Jason Weston. “A unified architecture for natural language processing: Deep neural networks with multitask learning.” Proceedings of the 25th international conference on Machine learning. 2008. http://machinelearning.org/archive/icml2008/papers/391.pdf. Note: this reference is given for historical reasons. But it is difficult to read!
