10
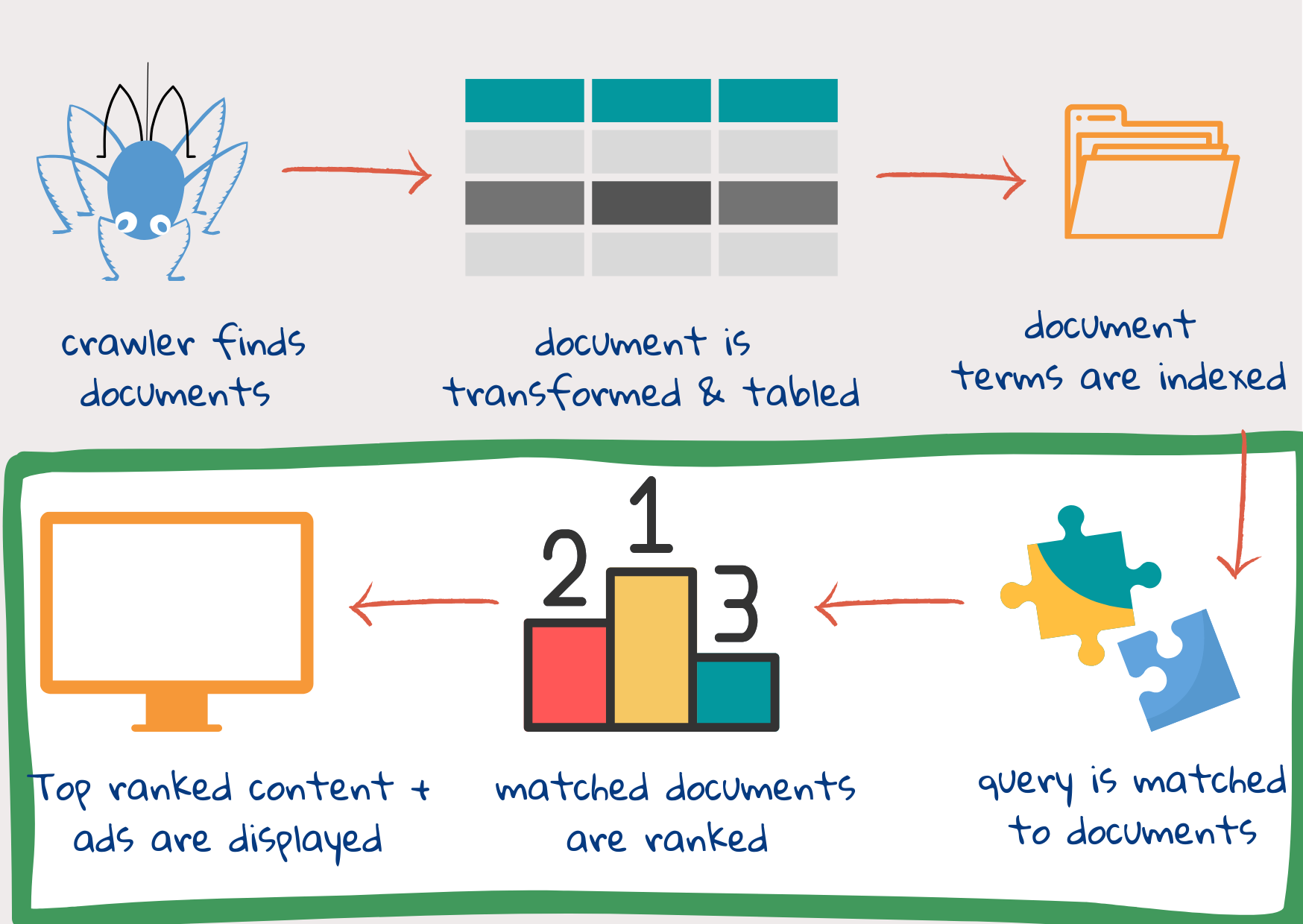
1. korak: spletni pajki poiščejo in prenesejo dokumente
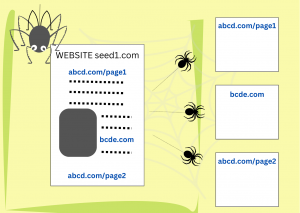
Ko uporabnik vnese iskalno poizvedbo, se v naslednjem koraku seveda ne loti pregledovanja vseh vsebin, ki so na voljo na internetu.1 Dokumenti na spletu so bili pregledani že prej, njihova vsebina pa je razdeljena in shranjena v različnih sklopih. Ko uporabnik vnese svojo poizvedbo, je treba le še uskladiti informacije v poizvedbi z informacijami v posameznih sklopih.
Spletni pajki so avtomatizirani programi oz. skripte, ki samostojno preiskujejo spletne strani na internetu. So deli računalniške kode, ki iščejo in prenašajo dokumente s spleta. Za začetek dobijo nabor naslovov spletnih strani (URL), do katerih morajo dostopati. To je začetni niz (angl. seed set). Ko prenesejo posamezno stran, na njej najprej preverijo, ali vsebuje povezave do drugih spletnih strani. Če jih vsebujejo, njihove naslove dodajo na svoj seznam opravil. Nato spet prenesejo na novo najdene strani in v njih spet iščejo povezave.
2. korak: dokument se preoblikuje v več delov
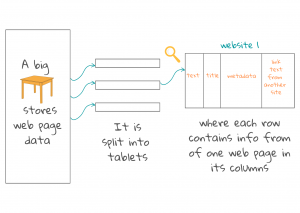 Dokument, ki ga prenese spletni pajek, je lahko jasno strukturirana spletna stran (napisana v jeziku html) z lastnim opisom vsebine, avtorja, datuma itd. Lahko pa je tudi slabo skenirana slika neke stare knjige iz knjižnice. Iskalniki običajno znajo prebrati približno sto različnih vrst dokumentov.1 Te pretvorijo v html ali xml in jih shranijo v tabele (v primeru Googla se takšna tabela imenuje BigTable).
Dokument, ki ga prenese spletni pajek, je lahko jasno strukturirana spletna stran (napisana v jeziku html) z lastnim opisom vsebine, avtorja, datuma itd. Lahko pa je tudi slabo skenirana slika neke stare knjige iz knjižnice. Iskalniki običajno znajo prebrati približno sto različnih vrst dokumentov.1 Te pretvorijo v html ali xml in jih shranijo v tabele (v primeru Googla se takšna tabela imenuje BigTable).
Vsaka tabela je sestavljena iz manjših tabel (angl. tablets). Vsaka vrstica v tabeli je namenjena eni spletni strani. Vrstice so razporejene v določenem vrstnem redu, ki se beleži skupaj z dnevnikom posodobitev. Vsak stolpec vsebuje določen tip informacij, povezanih s spletno stranjo, kar lahko pomaga pri usklajevanju vsebine z vsebino neke prihodnje iskalne poizvedbe. Stolpci vsebujejo:
- spletni naslov. Poleg tega, da spletni naslov omogoča identifikacijo vrstice v tabeli, nam lahko nekaj pove tudi že o vsebini izbrane strani. Če je stran identificirana kot domača stran, vsebina strani reprezentira celotno spletno mesto.
- naslove in posamezne besede v krepkem tisku, ki nakazujejo pomembno vsebino.
- metapodatke. To so informacije o strani, ki niso del glavne vsebine, npr. vrsta dokumenta (npr. e-pošta ali spletna stran), struktura dokumenta, dolžina dokumenta ipd. Html strani v opisih vsebujejo tudi (pogosto dragocene) ključne besede. Znanstveni in časopisni članki vsebujejo podatke o avtorjih in datum objave. Za slike in videoposnetke so značilne spet druge vrste metapodatkov.
- opise povezav z drugih spletnih strani na to stran. Kadar spletne strani vsebujejo povezave do drugih strani, so te običajno v obliki podčrtanega besedila (prav to je znak, da gre za hiperpovezavo). Temu pravimo sidrno besedilo. Kaže na to, kar je po mnenju avtorja osrednja vsebina strani. Sidrno besedilo je zapisano v ločenem stolpcu (več je povezav, več je stolpcev). Povezave se uporabljajo tudi za razvrščanje, ki razkriva, kako priljubljena je določena spletna stran (oglejte si npr. Google Pagerank, sistem razvrščanja za merjenje kakovosti in priljubljenosti spletnih strani).
- imena ljudi, podjetij ali organizacij ter lokacije, oznake za izražanje časa, datuma, količin, denarnih vrednosti itd. Algoritmi strojnega učenja znajo te podatke poiskati v katerikoli vsebini. Pri tem učni podatki vsebujejo označbe, ki jih je dodal človek.1
https:/ creativecommons.org/licenses/by-nc-sa/ 2.0/?ref=openverse..
Eden izmed stolpcev v takšni tabeli, pravzaprav najpomembnejši stolpec, vsebuje glavno vsebino dokumenta. Spletna stran lahko vsebuje še druge podatke, npr. zunanje povezave ali oglase, zato je treba najprej določiti glavno vsebino. Ena izmed temu namenjenih tehnik uporablja model strojnega učenja za “učenje” o tem, kaj predstavlja glavno vsebino na poljubni spletni strani.
Točne določene besede, ki jih vsebuje iskalna poizvedba, se bodo seveda ujemale z istimi besedami v najdenem spletnem dokumentu (podobno npr. omogoča funkcija iskanje/poišči v katerem koli urejevalniku besedil). Vendar to ni prav učinkovit način, saj ljudje za pogovor o isti stvari uporabljajo različne besede. Zgolj beleženje posameznih besed ne bo pomagalo ugotoviti, kako se te besede med seboj povezujejo, kar jim daje pomen. Navsezadnje nam pri sporazumevanju najbolj pomaga misel za besedami, in ne besede same. Zato vsi spletni iskalniki besedilo preoblikujejo tako, da se lažje ujema s pomenom besedila poizvedbe. Kasneje se tudi poizvedba obdela na podoben način.

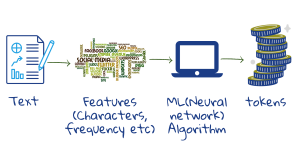
Iskalnik dele besed shrani kot žetone. Na ta način se zmanjša skupno število različnih žetonov, ki jih je treba shraniti. Modeli, ki so trenutno v uporabi, shranjujejo med 30.000 in 50.000 žetonov.2 Napačno črkovane besede so prepoznane, saj se deli teh besed še vedno ujemajo s shranjenimi žetoni. Tudi iskanje neznanih besed lahko obrodi rezultate, saj se njihovi posamezni deli lahko ujemajo z že shranjenimi žetoni.
Učne podatke za strojno učenje predstavljajo vzorčna besedila. Model izhaja iz posameznih znakov, presledkov in ločil ter združuje znake, ki se pogosto pojavljajo, in tako tvori nove žetone. Če število žetonov ni dovolj veliko, nadaljuje postopek združevanja, da zajame večje ali manj pogoste dele besed. Na ta način zajame večino besed, končnic in predpon. Ko dobi novo besedilo, ga stroj zlahka razdeli na žetone in shrani v pomnilniku.
3. korak: za lažji dostop se ustvari kazalo

Če si želite ogledati kopijo te licence, obiščite https:/ creativecommons.org/licenses/by-nd/2.0.
Ko so podatki shranjeni v tabeli (BigTable), se ustvari kazalo. Na koncu klasičnih, tiskanih učbenikov so v kazalu navedeni pomembni izrazi in številke strani, kjer te izraze najdemo. Spletni iskalniki pa razporedijo žetone in njihove lokacije v spletnem dokumentu. Pri tem lahko kazalu dodajo tudi določene statistične podatke, npr. kolikokrat se žeton pojavi v dokumentu, kako pomemben je ta žeton za dokument itd. Zapisane so lahko tudi informacije o položaju žetona v besedilu: ali je žeton v naslovu, ali v podnaslovu? Ali se zgoščeno pojavlja le v določenem delu besedila, ali ga najdemo v celotnem dokumentu? Ali en žeton vedno sledi točno določenemu drugemu žetonu?
Dandanes številni iskalniki uporabljajo kombinacijo tradicionalnega indeksiranja in jezikovnih modelov, ustvarjenih s pomočjo globokih nevronskih mrež. Slednje kodirajo semantične podrobnosti besedila in so odgovorne za boljše razumevanje poizvedb.3 Iskalnikom pomagajo preseči zgolj iskalni niz in se dokopati do zahteve, ki je v prvi vrsti sploh spodbudila poizvedbo.
Ti trije koraki na zelo poenostavljen način opisujejo to, kar imenujemo “indeksiranje” – torej iskanje, pripravo in shranjevanje dokumentov ter ustvarjanje kazala. V naslednjem poglavju so opisani koraki “razvrščanja”, tj. ujemanja iskalne poizvedbe z vsebino in prikazovanje rezultatov glede na pomembnost.
1 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015
2 Sennrich,R., Haddow, B., and Birch, A., Neural Machine Translation of Rare Words with Subword Units, In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics, 2016.
3 Metzler, D., Tay, Y., Bahri, D., Najork, M., Rethinking Search: Making Domain Experts out of Dilettantes, SIGIR Forum 55, 1, Article 13, June 2021.
