30 Habla de IA: procesamiento del lenguaje natural
El procesamiento del lenguaje natural ha sido un tema sobre el cual la investigación ha trabajado extensamente durante los últimos 50 años. Esto ha llevado al desarrollo de muchas herramientas que usamos todos los días:
- Procesadores de texto
- Corrección automática de gramática y ortografía
- Completado automático
- Reconocimiento óptico de caracteres (OCR)
Más recientemente, los chatbots, asistentes domésticos y herramientas de traducción automática han estado teniendo un enorme impacto en todas las áreas.
Durante mucho tiempo, la investigación y la industria estuvieron estancadas por la complejidad intrínseca del lenguaje. Al final del siglo XX, las gramáticas de un idioma, escritas por expertos, podrían tener hasta 50,000 reglas. Estos sistemas expertos demostraban que la tecnología podría marcar una diferencia, pero las soluciones robustas eran demasiado complejas para ser desarrolladas.
Por otro lado, el reconocimiento de voz necesitaba poder hacer uso de datos acústicos y transformarlos en texto. ¡Con la variedad de hablantes que uno podría encontrar, una tarea realmente difícil!
Los investigadores entendieron que si teníamos un modelo para el idioma deseado, las cosas serían más fáciles. Si conociéramos las palabras del idioma, cómo se forman las oraciones, entonces sería más fácil encontrar la oración correcta de un conjunto de candidatos para coincidir con una expresión dada, o para producir una traducción válida de un conjunto de posibles secuencias de palabras.
Otro aspecto crucial ha sido el de la semántica. La mayor parte del trabajo que podemos hacer para resolver preguntas lingüísticas es superficial; los algoritmos producirán una respuesta basada en algunas reglas sintácticas locales. Si al final, el texto no significa nada, así sea. Algo similar puede suceder cuando leemos un texto de algunos estudiantes: ¡podemos corregir los errores sin realmente entender de qué trata el texto! Un verdadero desafío es asociar significado al texto y, cuando sea posible, a las oraciones pronunciadas.
Hubo un resultado sorprendente en 20081. Un único modelo de lenguaje podría aprenderse de una gran cantidad de datos y usarse para una variedad de tareas lingüísticas. De hecho, ese modelo único funcionó mejor que los modelos entrenados para tareas específicas.
El modelo era una red neuronal profunda. ¡Nada tan profundo como los modelos utilizados hoy en día! Pero suficiente para convencer a la investigación y la industria de que el AA, y más específicamente el aprendizaje profundo, iba a ser la respuesta a muchas preguntas en PLN.
Desde entonces, el procesamiento del lenguaje natural ha dejado de seguir un enfoque basado en modelos y ha estado casi siempre basado en un enfoque basado en datos.
Tradicionalmente, las principales tareas lingüísticas se pueden descomponer en dos familias: aquellas que involucran la construcción de modelos y aquellas que involucran la decodificación.
Construcción de modelos
Para transcribir, responder preguntas, generar diálogos o traducir, necesitas poder saber si «Je parle Français» es de hecho una oración en francés. Y como con los idiomas hablados, las reglas de gramática no siempre se siguen con precisión, por lo que la respuesta tiene que ser probabilística. Una oración puede ser más o menos francesa. Esto permite al sistema producir diferentes oraciones candidatas (como la transcripción de un sonido, o la traducción de una oración) y la probabilidad se da como una puntuación asociada con cada candidato. Podemos tomar la oración con la puntuación más alta o combinar la puntuación con otras fuentes de información (también podemos estar interesados en de qué trata la oración).
Los modelos de lenguaje hacen esto, y las probabilidades se construyen a partir de algoritmos de AA. Y por supuesto, cuanto más datos haya, mejor. Para algunos idiomas hay muchos datos a partir de los cuales construir modelos de lenguaje. Para otros, este no es el caso; estos son idiomas con recursos insuficientes.
En el caso de la traducción, queremos no dos sino tres modelos: un modelo de lenguaje para cada idioma y otro modelo para las traducciones, informándonos cuáles son las mejores traducciones de fragmentos de lenguaje. Estos son difíciles de producir cuando los datos son escasos. Si los modelos para pares de idiomas comunes son más fáciles de construir, este no será el caso para idiomas que no se hablan frecuentemente juntos (como el portugués y el esloveno). Una salida típica de esto es usar un idioma pivote (típicamente inglés) y traducir a través de este idioma pivote: del portugués al inglés y luego del inglés al esloveno. Esto llevará a resultados inferiores ya que los errores se acumulan.
Decodificación
La decodificación es el proceso en el cual un algoritmo toma la secuencia de entrada (que puede ser señal o texto) y, consultando los modelos, toma una decisión, que a menudo será un texto de salida. Aquí hay algunas consideraciones algorítmicas: en muchos casos, la transcripción y la traducción deben ocurrir en tiempo real y disminuir el retraso temporal es un tema clave. Así que hay espacio para mucha IA.
De extremo a extremo
Hoy en día, el enfoque de construir estos componentes por separado y combinarlos más tarde ha sido reemplazado por enfoques de extremo a extremo en los cuales el sistema transcribirá/traducirá/interpretará la entrada a través de un modelo único. Actualmente, tales modelos son entrenados por redes neuronales profundas, que pueden ser enormes. ¡Se informa que el modelo GPT3 más grande actualmente comprende varios cientos de millones de parámetros!
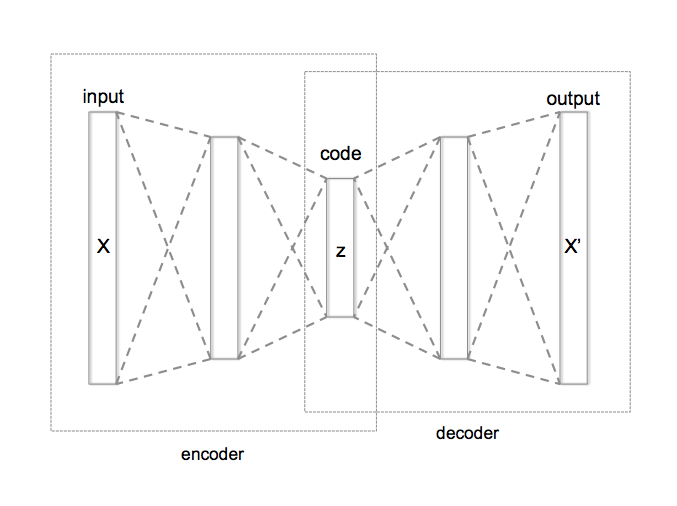
Intentemos entender la intuición detrás de este proceso. Supongamos que tenemos algunos datos. Estos datos brutos pueden codificarse de alguna manera. Pero la codificación puede ser redundante, e incluso costosa. Construyamos ahora una máquina particular, llamada un auto-codificador (ver diagrama a la izquierda). Esta máquina será capaz de tomar un texto, comprimirlo en un pequeño vector (esta es la parte del codificador), y luego descomprimir el vector (la parte del decodificador) y devolver un texto que de alguna manera se acerque al texto original. La idea es que este mecanismo hará que el vector intermedio sea significativo, con dos propiedades deseables: un vector razonablemente pequeño que ‘contiene’ la información en el texto inicial.
El futuro
Un ejemplo de un proceso de extremo a extremo que podría estar disponible pronto será la capacidad de realizar la siguiente tarea: te escuchará hablar tu idioma, transcribirá tu texto, lo traducirá a un idioma que no conoces, entrenará un sistema de síntesis de voz a tu voz, y hará que tu propia voz hable el texto correspondiente en una nueva oración. Aquí hay dos ejemplos producidos por investigadores de la Universidad Politécnica de Valencia, España, en los que se utiliza el modelo de voz del propio hablante para hacer el doblaje.
Algunas consecuencias para la educación
El progreso constante del procesamiento del lenguaje natural es notable. Hace solo diez años nos reíamos de las traducciones propuestas por la IA. Cada vez es más difícil encontrar errores tan obvios hoy en día. Las técnicas de reconocimiento de voz y de reconocimiento de caracteres también están mejorando rápidamente.
Los desafíos semánticos todavía están ahí, y responder preguntas que requieren una comprensión profunda de un texto todavía no es del todo correcto. Pero las cosas van en la dirección correcta. Esto significa que el profesor debería esperar que algunas de las siguientes afirmaciones sean ciertas pronto, ¡si es que ya no lo son!
- Un estudiante tomará un texto complejo y obtendrá (con IA) una versión simplificada; el texto incluso puede ser personalizado y usar términos, palabras y conceptos a los que el estudiante esté acostumbrado;
- Un estudiante podrá encontrar un texto, copiarlo y obtener un texto que diga las mismas cosas pero indetectable por una herramienta antiplagio;
- Los videos producidos en cualquier parte del mundo serán accesibles a través de doblaje automático en cualquier idioma. Esto significa que nuestros estudiantes estarán expuestos a material de aprendizaje construido en nuestro idioma y también por material inicialmente diseñado para otro sistema de aprendizaje en una cultura diferente;
- Escribir ensayos podría convertirse en una tarea del pasado, ya que las herramientas permitirán escribir sobre cualquier tema.
Está claro que la IA estará lejos de ser perfecta, y el experto detectará que incluso si el lenguaje es correcto, el flujo de ideas no lo será. Pero enfrentémoslo: durante el curso de la educación, ¿cuánto tiempo llevará que nuestros estudiantes alcancen ese nivel?
1 Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing: Deep neural networks with multitask learning. En Proceedings of the 25th International Conference on Machine Learning (pp. 160–167). ACM. http://machinelearning.org/archive/icml2008/papers/391.pdf
Nota: esta referencia se da por razones históricas. ¡Pero es difícil de leer!
