17 Habla de IA: sistemas basados en datos -Parte 2
El diseño e implementación de un proyecto centrado en datos se puede desglosar en seis pasos. Hay muchas idas y vueltas entre los pasos y todo el proceso puede necesitar ser repetido múltiples veces para hacerlo correctamente.
Para ser efectivos en el aula, equipos multidisciplinarios con profesores, expertos pedagógicos y científicos de la computación deberían estar involucrados en cada paso del proceso1. Se necesitan expertos humanos para identificar la necesidad y diseñar el proceso, para diseñar y preparar los datos, seleccionar algoritmos de ML, para interpretar críticamente los resultados y para planificar cómo usar la aplicación2.
1) Entendiendo el contexto educativo
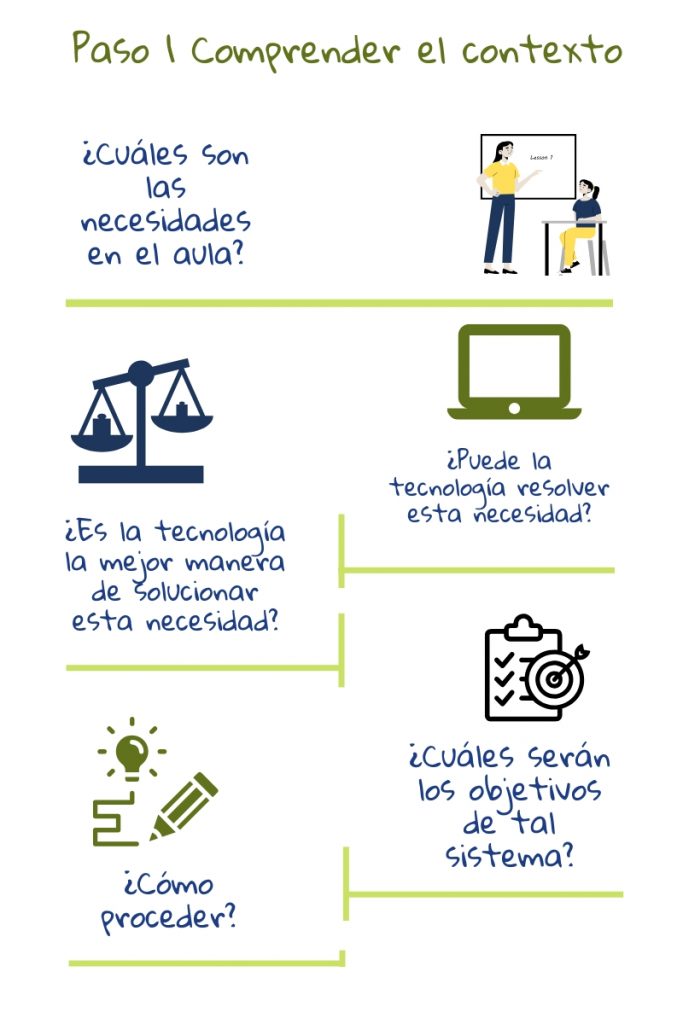
El primer paso en el diseño de una herramienta AIED es entender las necesidades en el aula. Una vez que los objetivos están establecidos, se tiene que ver cómo pueden ser alcanzados: qué factores considerar y cuales ignorar. Cualquier solución basada en datos está sesgada hacia fenómenos que pueden ser fácilmente calculados y estandarizados3. Por lo tanto, cada decisión tiene que ser discutida por los profesores que usarán la herramienta, por expertos en pedagogía que pueden asegurar que todas las decisiones estén fundamentadas en teoría probada, y por científicos de la computación que entienden cómo funcionan los algoritmos.
Hay muchas idas y vueltas entre los dos primeros pasos ya que lo que es posible también dependerá de qué datos están disponibles2. Además, el diseño de herramientas educativas también está sujeto a leyes que imponen restricciones sobre el uso de datos y tipos de algoritmos que pueden ser usados.
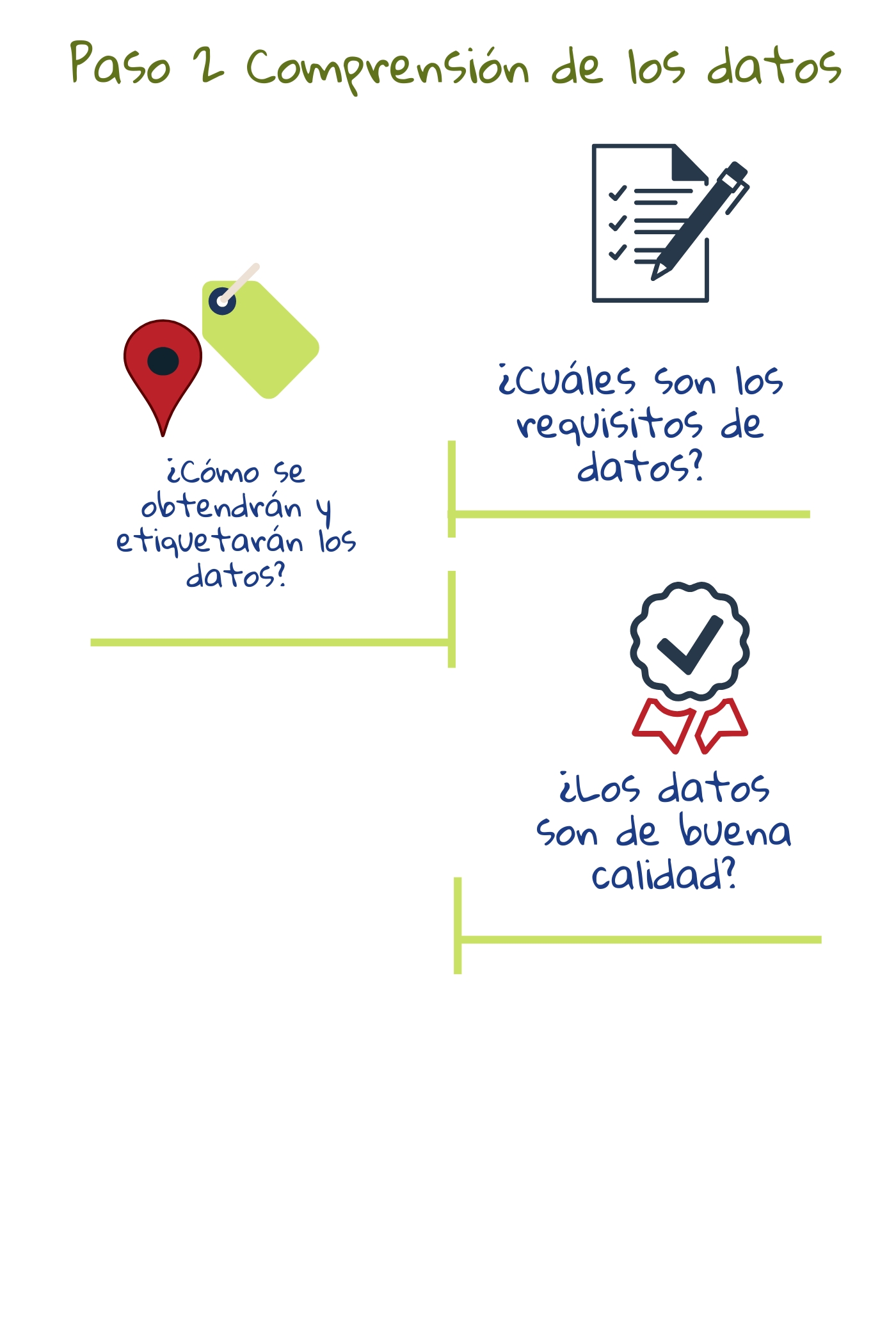
2) Entendiendo los datos
Una vez que los objetivos y factores contribuyentes son identificados, el enfoque se desplaza a qué datos son requeridos; cómo serán obtenidos y etiquetados; cómo se manejará la privacidad, y cómo se medirá la calidad de los datos3. Para que una aplicación de aprendizaje automático sea exitosa, los conjuntos de datos tienen que ser lo suficientemente grandes, diversos y bien etiquetados.

El aprendizaje automático requiere datos para entrenar el modelo y datos para trabajar o predecir con. Algunas tareas de ML como el reconocimiento facial y de objetos ya tienen muchas bases de datos privadas y públicas disponibles para el entrenamiento.
Si no están ya disponibles en una forma utilizable, los conjuntos de datos existentes pueden tener que ser ampliados o reetiquetados para ajustarse a las necesidades del proyecto. Si no, pueden tener que ser creados y etiquetados desde cero conjuntos de datos dedicados. Las huellas digitales generadas por el estudiante al usar una aplicación también podrían ser usadas como una de las fuentes de datos.
En cualquier caso, los datos y características relevantes al problema tienen que ser cuidadosamente identificados2. Características irrelevantes o redundantes pueden empujar a un algoritmo a encontrar patrones falsos y afectar el rendimiento del sistema2. Dado que la máquina solo puede encontrar patrones en los datos que se le dan, elegir el conjunto de datos también define implícitamente cuál es el problema4. Si hay muchos datos disponibles, se tiene que seleccionar un subconjunto con la ayuda de técnicas estadísticas y los datos verificados para evitar errores y sesgos.
Como ejemplo de datos de entrenamiento malos, en una historia de los primeros días de la visión por computadora, un modelo fue entrenado para discriminar entre imágenes de tanques rusos y americanos. Su alta precisión fue luego encontrada debido al hecho de que los tanques rusos habían sido fotografiados en un día nublado y los americanos en un día soleado4.
Por lo tanto, el conjunto de datos elegido tiene que ser verificado por calidad, teniendo en cuenta por qué fue creado, qué contiene, cuáles son los procesos usados para recolectar, limpiar y etiquetar, distribución y mantenimiento4. Las preguntas clave a hacer incluyen ¿Los conjuntos de datos son aptos para los propósitos previstos? y ¿Contienen los conjuntos de datos peligros ocultos que pueden hacer que los modelos sean sesgados o discriminatorios?3
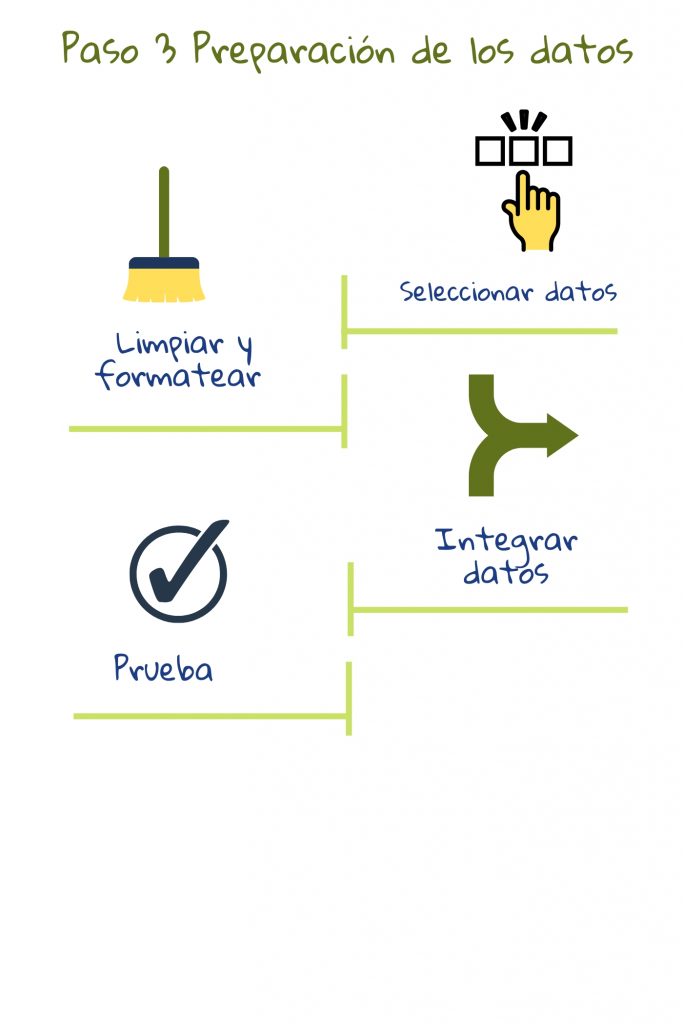
3) Preparando los datos
La preparación de datos implica crear conjuntos de datos fusionando datos disponibles de diferentes lugares, ajustando inconsistencias (por ejemplo, algunos puntajes de pruebas podrían estar en una escala de uno a diez, mientras otros se dan como porcentaje) y buscando valores faltantes o extremos. Luego, se podrían realizar pruebas automatizadas para verificar la calidad de los conjuntos de datos. Esto incluye verificar fugas de privacidad y correlaciones o estereotipos imprevistos2. Los conjuntos de datos también podrían ser divididos en conjuntos de entrenamiento y de prueba en esta etapa. El primero se usa para entrenar el modelo y el segundo para verificar su rendimiento. Probar en el conjunto de entrenamiento sería como dar el examen el día antes como ejercicio: el rendimiento del estudiante en el examen no indicará su comprensión2.
4) Modelado
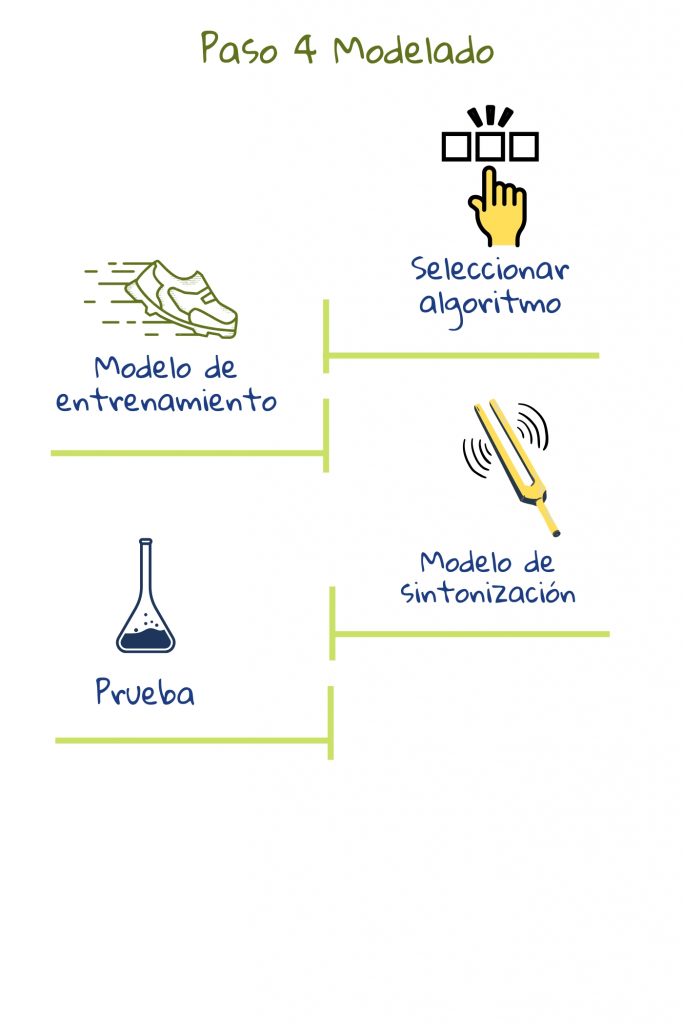
En este paso, se usan algoritmos para extraer patrones en los datos y crear modelos. Usualmente, se prueban diferentes algoritmos para ver qué funciona mejor. Estos modelos pueden entonces ser puestos en uso para hacer predicciones sobre nuevos datos.
En la mayoría de los proyectos, los modelos iniciales descubren problemas en los datos que requieren revisión de los pasos 2 y 32. Mientras haya una fuerte correlación entre las características de los datos y el valor de salida, es probable que un algoritmo de Aprendizaje Automático genere buenas predicciones.
Estos algoritmos usan técnicas avanzadas de estadística y computación para procesar datos. Los programadores tienen que ajustar la configuración y probar diferentes algoritmos para obtener los mejores resultados. Tomemos una aplicación que detecta trampas. Un falso positivo es cuando a un estudiante que no hizo trampa se le marca. Un falso negativo es cuando a un estudiante que hizo trampa no se le marca. Los diseñadores del sistema pueden ajustar el modelo para minimizar ya sea falsos positivos, donde algunos comportamientos de trampa podrían ser pasados por alto, o falsos negativos, donde incluso casos dudosos son marcados5. La afinación depende entonces de lo que queremos que el sistema haga.
5) Evaluación
Durante la etapa de modelado, cada modelo puede ser ajustado para precisión de predicción en el conjunto de datos de entrenamiento. Luego los modelos son probados en el conjunto de prueba y se elige un modelo para su uso. Este modelo también es evaluado en cómo cumple con las necesidades educativas: ¿Se cumplen los objetivos establecidos en el paso 1? ¿Hay algún problema imprevisto? ¿Es la calidad buena? ¿Podría algo ser mejorado o hecho de otra manera? ¿Se necesita un rediseño? El objetivo principal es decidir si la aplicación puede ser desplegada en los espacios educativos. Si no, todo el proceso se repite2.
6) Despliegue
El paso final de este proceso es ver cómo integrar la aplicación basada en datos con el sistema educativo para obtener los máximos beneficios, tanto con respecto a la infraestructura técnica como a las prácticas de enseñanza.
Aunque se da como el paso final, todo el proceso es interactivo. Después del despliegue, el modelo debería ser revisado regularmente para verificar si todavía es relevante para el contexto. Las necesidades, procesos o modos de captura de datos podrían cambiar afectando la salida del sistema. Por lo tanto, la aplicación debería ser revisada y actualizada cuando sea necesario. El sistema debería ser monitoreado continuamente por su impacto en el aprendizaje, la enseñanza y la evaluación6.

Las pautas éticas sobre el uso de IA y datos para profesores enfatizan que los sistemas educativos deberían estar en contacto con el proveedor de servicios de IA a lo largo del ciclo de vida del sistema de IA, incluso antes del despliegue. Debería pedir documentación técnica clara y buscar aclaraciones sobre puntos no claros. Se debería hacer un acuerdo para soporte y mantenimiento, y se debería asegurar que el proveedor cumpla con todas las obligaciones legales6.
Nota: Tanto los pasos listados aquí como la ilustración están adaptados de las etapas y tareas de ciencia de datos CRISP-DM (basado en la figura 3 en Chapman, Clinton, Kerber, et al. 1999) como se describe en 2.
1 du Boulay, B., Poulovassilis, A., Holmes, W., & Mavrikis, M. (2018). Artificial intelligence and big data technologies to close the achievement gap. En R. Luckin (Ed.), Enhancing learning and teaching with technology (pp. 256–285). UCL Institute of Education Press. https://discovery.ucl.ac.uk/id/eprint/10058950/1/Enhancing-learning-and-teaching-with-technology.pdf
2 Kelleher, J. D., & Tierney, B. (2018). Data science. MIT Press.
3 Hutchinson, B., Smart, A., Hanna, A., Denton, E., Greer, C., Kjartansson, O., Barnes, P., & Mitchell, M. (2021). Towards accountability for machine learning datasets: Practices from software engineering and infrastructure. En Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 560–575). Association for Computing Machinery. https://doi.org/10.1145/3442188.3445880.
4 Barocas, S., Hardt, M., & Narayanan, A. (2023). Fairness and machine learning: Limitations and opportunities. MIT Press. https://fairmlbook.org/
5 Schneier, B. (2015). Data and Goliath: The hidden battles to capture your data and control your world. W. W. Norton & Company.
6 European Commission. (2022, October). Ethical guidelines on the use of artificial intelligence and data in teaching and learning for educators. Publications Office of the European Union. https://education.ec.europa.eu/document/ethical-guidelines-on-the-use-of-ai-and-data-in-teaching-and-learning-for-educators
