9 Habla de IA: aprendizaje automático
Un algoritmo es una secuencia fija de instrucciones para llevar a cabo una tarea. Descompone la tarea en pasos fáciles y sin confusión, como una receta bien escrita.
Los lenguajes de programación son idiomas que una computadora puede seguir y ejecutar. Actúan como un puente, entre lo que nosotros y una máquina podemos entender. En última instancia, son interruptores que se encienden y apagan. Para una computadora, imágenes, videos, instrucciones son todos 1s (interruptor encendido) y 0s (interruptor apagado).
Cuando se escribe en un lenguaje de programación, un algoritmo se convierte en un programa. Las aplicaciones son programas escritos para un usuario final.
Los programas convencionales toman datos y siguen las instrucciones para dar una salida. Muchos de los primeros programas de IA eran convencionales. Dado que las instrucciones no pueden adaptarse a los datos, estos programas no eran muy buenos en aspectos como predecir basándose en información incompleta y el Procesamiento del Lenguaje Natural (PLN).
Diagrama “A Machine Learns” [Diagrama]. En AI Speak: Machine Learning, en AI for Teachers: an Open Textbook, traducido al español por Rodriguez Enríquez. Licenciada bajo CC BY 4.0. https://creativecommons.org/licenses/by/4.0/
Un motor de búsqueda está impulsado tanto por algoritmos convencionales como por algoritmos de aprendizaje automático. A diferencia de los programas convencionales, los algoritmos de aprendizaje automática (ML por sus siglas en inglés) analizan los datos en busca de patrones que utilizan tanto como reglas para tomar decisiones o efectuar predicciones. Así, basándose en datos, en buenos y en malos ejemplos, encuentran su propia receta.
Estos algoritmos son adecuados para situaciones con mucha complejidad y datos faltantes. También pueden monitorear su propio rendimiento y usar esta retroalimentación para mejorar.
Esto no es muy diferente de los seres humanos, especialmente cuando vemos a los bebés aprendiendo habilidades fuera del sistema educativo convencional. Los bebés observan, repiten, aprenden, prueban su aprendizaje y mejoran. Donde es necesario, improvisan.
Pero la similitud entre máquinas y humanos es superficial. «Aprender» desde una perspectiva humana es diferente, y mucho más matizado y complejo que «aprender» para la máquina.
Un problema de clasificación
Licencia: CC BY-SA 2.0. https://creativecommons.org/licenses/by-sa/2.0/)
Una tarea común que se utiliza una aplicación de ML para realizar es la clasificación: ¿es esta una foto de un perro o un gato? ¿Este estudiante está teniendo dificultades o pasará el examen? Hay dos o más grupos, y la aplicación tiene que clasificar nuevos datos en uno de ellos.
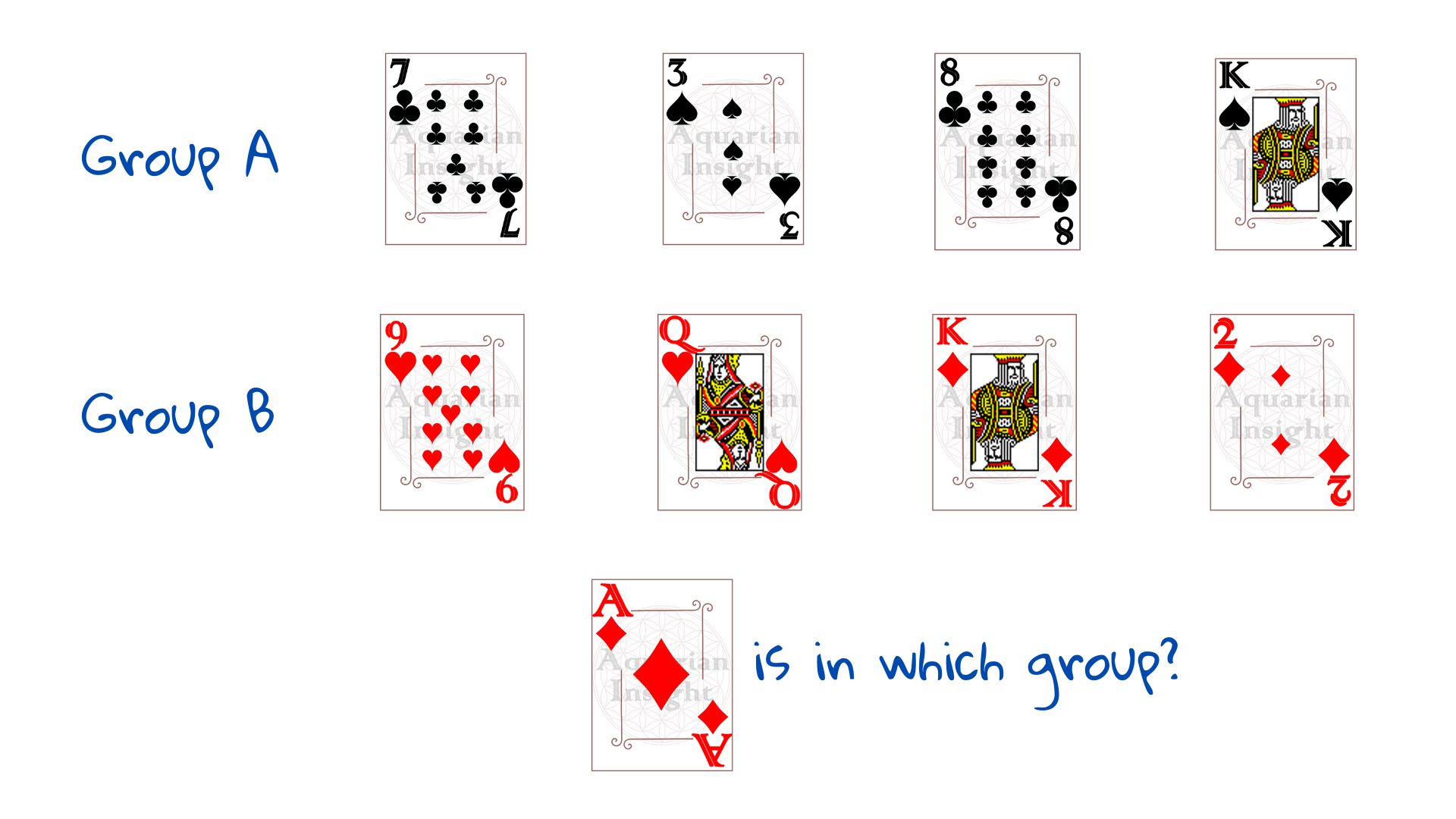
Tomemos el ejemplo de un paquete de cartas de jugar – grupo A y grupo B – dividido en dos montones y siguiendo algún patrón. Necesitamos clasificar una nueva carta, el as de diamantes, como perteneciente al grupo A o al grupo B.
Primero, necesitamos entender cómo se dividen los grupos, necesitamos ejemplos. Saquemos cuatro cartas del grupo A y cuatro del grupo B. Estos ocho casos de ejemplo forman nuestro conjunto de entrenamiento – datos que nos ayudan a ver el patrón – «entrenándonos» para ver el resultado.
Tan pronto como se nos muestra la disposición a la derecha, la mayoría de nosotros adivinaríamos que el as de diamantes pertenece al Grupo B. No necesitamos instrucciones, porque el cerebro humano es excelente encontrando patrones. ¿Cómo lo haría una máquina?
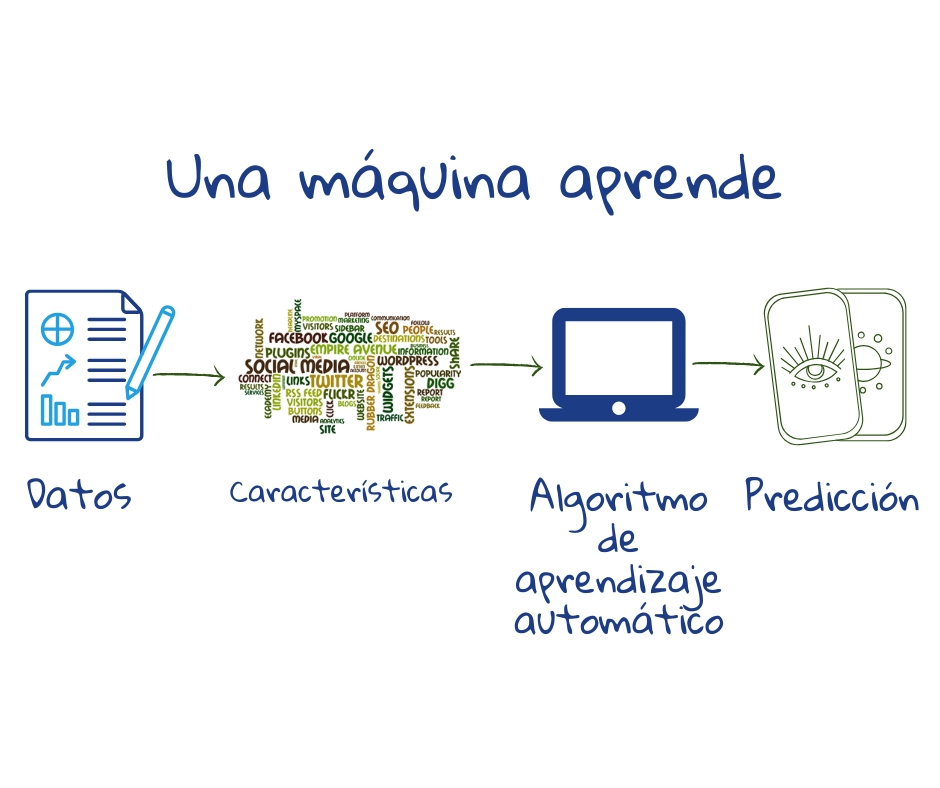
Los algoritmos de ML se basan en poderosas teorías estadísticas. Diferentes algoritmos se basan en diferentes ecuaciones matemáticas que deben ser elegidas cuidadosamente para ajustarse a la tarea en cuestión. Es el trabajo del programador elegir los datos, analizar qué características de los datos son relevantes para el problema particular y elegir el algoritmo de ML correcto.
La importancia de los datos
Licencia: Creative Commons Atribución-CompartirIgual 2.0 CC BY-SA 2.0. https://creativecommons.org/licenses/by-sa/2.0/
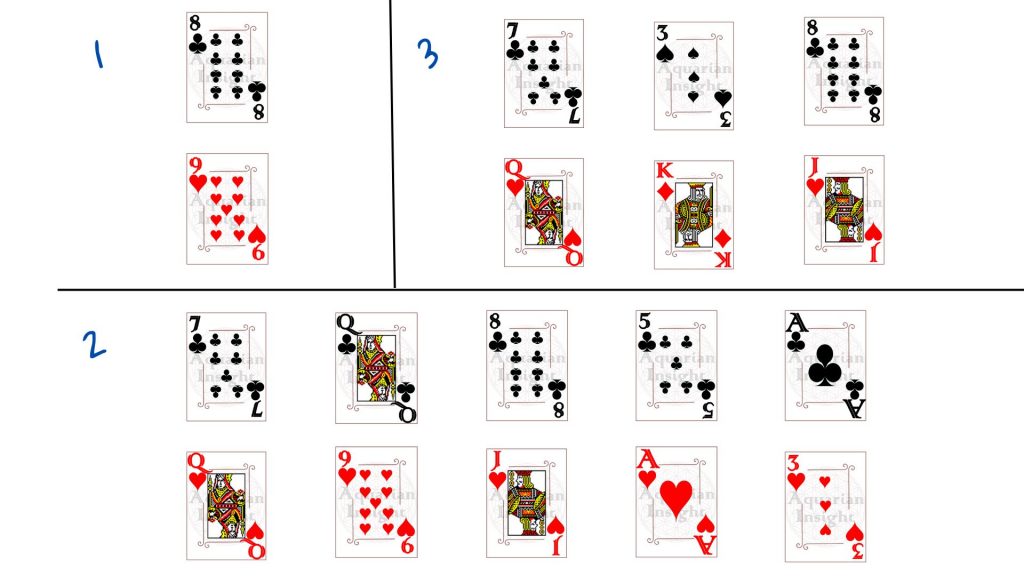
La selección de cartas anterior podría haber sido errónea de varias maneras. Por favor, refiérete a la imagen. 1 tiene muy pocas cartas, no sería posible adivinar. 2 tiene más cartas pero todas del mismo palo, no hay manera de saber dónde irían los diamantes. Si los grupos no fueran del mismo tamaño, 3 podría muy bien significar que las cartas numéricas están en el grupo A y las cartas con imágenes en el grupo B.
Usualmente, los problemas de aprendizaje automático son más abiertos e involucran conjuntos de datos mucho más grandes que un paquete de cartas. Los conjuntos de entrenamiento tienen que ser elegidos con la ayuda del análisis estadístico, o de lo contrario se introducen errores. Una buena selección de datos es crucial para una buena aplicación de ML, más aun que para otros tipos de programas. El aprendizaje automático necesita una gran cantidad de datos relevantes. Como mínimo absoluto, un modelo básico de aprendizaje automático debería contener diez veces tantos puntos de datos como el número total de características1. Dicho esto, el ML también está particularmente equipado para manejar datos ruidosos, desordenados y contradictorios.
Extracción de características
Cuando anteriormente se muestran los ejemplos de los Grupos A y B, lo primero que podrías haber notado podría ser el color de las cartas. Luego el número o letra y el palo. Para un algoritmo, todas estas características tienen que ser ingresadas específicamente. No puede saber automáticamente qué es importante para el problema.
Al seleccionar las características de interés, los programadores tienen que hacerse muchas preguntas. ¿Cuántas características son demasiado pocas para ser útiles? ¿Cuántas características son demasiadas? ¿Qué características son relevantes para la tarea? ¿Cuál es la relación entre las características elegidas, es una característica dependiente de la otra? Con las características elegidas, ¿es posible que la salida sea precisa?
El proceso
Cuando el programador está creando la aplicación, toma datos, extrae características de ellos, elige un algoritmo de aprendizaje automático apropiado (función matemática que define el proceso), y lo entrena usando datos etiquetados (en el caso de que el resultado sea conocido, como el grupo A o B) para que la máquina entienda el patrón detrás del problema.
Para una máquina, entender toma la forma de un conjunto de números –pesos– que asigna a cada característica. Con la asignación correcta de pesos, puede calcular la probabilidad de que una nueva carta esté en el grupo A o B. Típicamente, durante la etapa de entrenamiento, el programador ayuda a la máquina cambiando manualmente algunos valores. Esto se denomina ajustar la aplicación.
Una vez hecho esto, el programa tiene que ser probado antes de ser puesto en uso. Para ello, los datos etiquetados que no se usaron para el entrenamiento se le darían al programa. Esto se llama el conjunto de prueba. El rendimiento de la máquina en predecir la salida se mediría entonces. Una vez determinado como satisfactorio, el programa puede ser puesto en uso: está listo para tomar nuevos datos y tomar una decisión o predicción basada en estos datos.
¿Puede un modelo funcionar de manera diferente en conjuntos de datos de entrenamiento y de prueba? ¿Cómo afecta el número de características al rendimiento en ambos? Mira este video para descubrirlo.
El rendimiento en tiempo real se monitorea y mejora continuamente (los pesos de las características se ajustan para obtener una mejor salida). A menudo, el rendimiento en tiempo real da resultados diferentes que cuando el ML se prueba con datos ya disponibles. Dado que experimentar con usuarios reales es costoso, requiere mucho esfuerzo y a menudo es arriesgado, los algoritmos siempre se prueban usando datos históricos de usuarios, que pueden no ser capaces de evaluar el impacto en el comportamiento del usuario1. Por eso es importante hacer una evaluación exhaustiva de las aplicaciones de aprendizaje automático, una vez en uso:
¿Te interesa hacer algo de aprendizaje automático práctico? Prueba esta actividad.
1 Theobald, O. (2021). Machine learning for absolute beginners: A plain English introduction (2ª ed., p. 24) [Kindle edition]. Scatterplot Press. Disponible en PDF gratuito: https://mrce.in/ebooks/Machine%20Learning%20for%20Absolute%20Beginners.pdf
2 Konstan, J. A., & Terveen, L. G. (2021). Human‑centered recommender systems: Origins, advances, challenges, and opportunities. AI Magazine, 42(3), 31–42. https://doi.org/10.1609/aimag.v42i3.18142

.jpg){kind=link}