10 Habla de IA: indexación de motores de búsqueda
Un motor de búsqueda toma palabras clave (la consulta de búsqueda) introducidas en el cuadro de búsqueda y trata de encontrar los documentos web que responden a la información. Luego muestra la información de forma accesible, con la página más relevante en la parte superior. Para hacer esto, el motor de búsqueda tiene que comenzar por encontrar documentos en la web y etiquetarlos para que sean fáciles de recuperar. Veamos en líneas generales lo que implica este proceso.
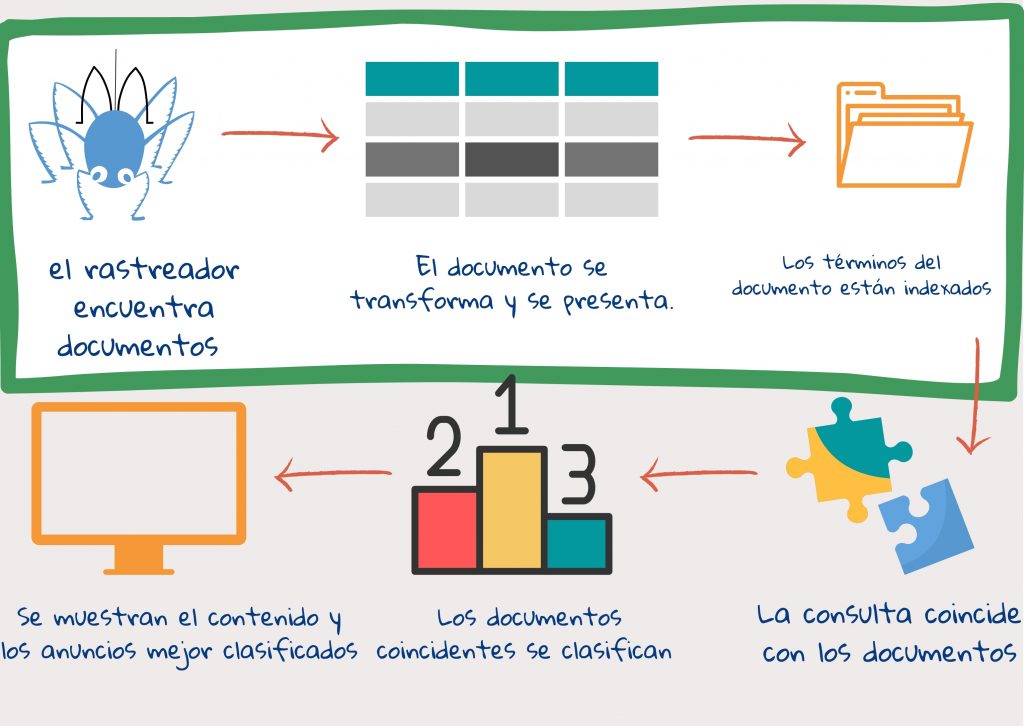
Paso 1: Los rastreadores web encuentran y descargan documentos
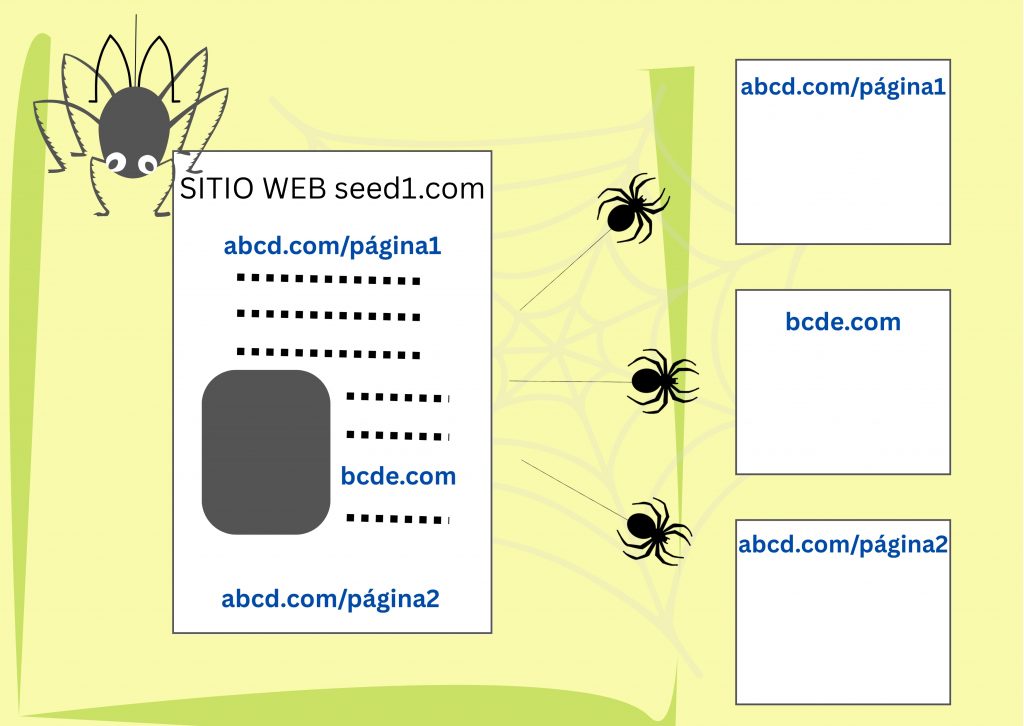
Después de que un usuario introduce una consulta de búsqueda, es demasiado tarde para mirar todo el contenido disponible en internet1. Los documentos web se miran de antemano, y su contenido se desglosa y almacena en diferentes espacios.
Diagrama sobre cómo los motores de búsqueda rastrean e indexan páginas web [Ilustración]. En AI Speak: Search Engine Indexing, de AI for Teachers: an Open Textbook, traducido al español por Rodriguez Enríquez. Licencia Creative Commons Atribución–CompartirIgual 4.0 Internacional (CC BY-SA 4.0). https://creativecommons.org/licenses/by-sa/4.0/
Una vez que la consulta está disponible, todo lo que necesita hacerse es coincidir lo que se consulta con lo que está en los espacios.
Los rastreadores web son piezas de código que encuentran y descargan documentos de la web. Comienzan con un conjunto de direcciones de sitios web (URL) y buscan en ellas enlaces a nuevas páginas web. Luego, descargan y examinan las nuevas páginas en busca de más enlaces. Siempre que la lista inicial sea lo suficientemente diversa, los rastreadores terminan visitando cada sitio que les permite el acceso, a menudo varias veces, buscando actualizaciones.
Paso 2: el documento se transforma en múltiples piezas
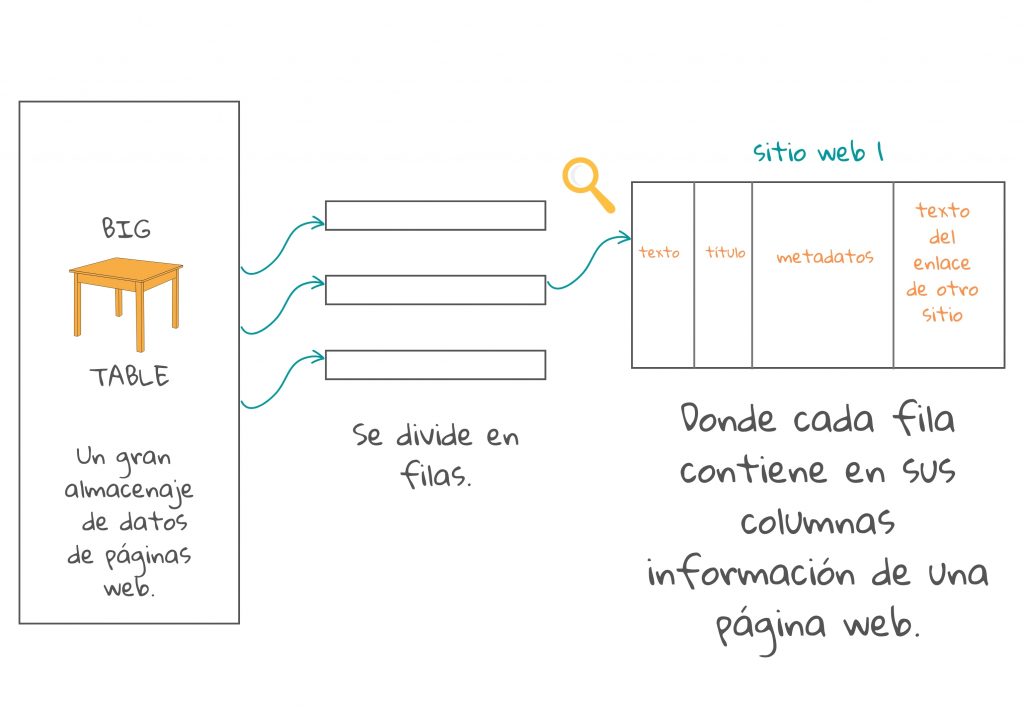
El documento descargado por el rastreador puede ser una página web claramente estructurada con su propia descripción de contenido, autor, fecha, etc. También puede ser una imagen mal escaneada de un libro antiguo de una biblioteca. Los motores de búsqueda suelen leer cien tipos diferentes de documentos1. Los convierten en código html o xml y los almacenan en tablas (llamadas BigTable en el caso de Google).
Una tabla está compuesta por secciones más pequeñas llamadas tabletas en las que cada fila de la tableta está dedicada a una página web. Estas filas se organizan en algún orden que se registra junto con un registro de actualizaciones. Cada columna tiene información específica relacionada con la página web que puede ayudar a coincidir el contenido del documento con los contenidos de una futura consulta. Las columnas contienen:
-
- La dirección del sitio web que puede, por sí misma, dar una buena descripción de los contenidos en la página, si es una página principal con contenido representativo o una página secundaria con contenido asociado;
- Títulos, encabezados y palabras en negrita que describen contenido importante;
- Metadatos de la página. Esta es información sobre la página que no forma parte del contenido principal, como el tipo de documento (por ejemplo, correo electrónico o página web), estructura del documento y características como la longitud del documento, palabras clave, nombres de autores y fecha de publicación;
- Descripción de enlaces de otras páginas a esta página que proporcionan texto sucinto sobre diferentes aspectos del contenido de la página. Más enlaces, más descripciones y más columnas utilizadas. La presencia de enlaces también se utiliza para la clasificación, para determinar cuán popular es una página web. (Echa un vistazo a PageRank de Google, un sistema de clasificación que utiliza enlaces hacia y desde una página para medir la calidad y popularidad).
- Nombres de personas, empresas u organizaciones, ubicaciones, direcciones, expresiones de tiempo y fecha, cantidades y valores monetarios, etc. Los algoritmos de aprendizaje automático pueden ser entrenados para encontrar estas entidades en cualquier contenido utilizando datos anotados por un ser humano1.
Licencia: Creative Commons Atribución-NoComercial-CompartirIgual 2.0 (CC BY-NC-SA 2.0). https://creativecommons.org/licenses/by-nc-sa/2.0/
Una columna de la tabla, quizás la más importante, contiene el contenido principal del documento. Esto tiene que ser identificado en medio de todos los enlaces externos y anuncios. Una técnica utiliza un modelo de aprendizaje automático para «aprender» cuál es el contenido principal en cualquier página web.
Por supuesto, podemos coincidir palabras exactas de la consulta con las palabras en un documento web, como el botón Buscar en cualquier procesador de textos. Pero esto no es muy efectivo, ya que las personas usan diferentes palabras para hablar sobre el mismo objeto. Simplemente registrar las palabras por separado no ayudará a capturar cómo estas palabras se combinan entre sí para crear significado. En última instancia, es el pensamiento detrás de las palabras lo que nos ayuda a comunicarnos, y no las palabras mismas. Por lo tanto, todos los motores de búsqueda transforman el texto de una manera que facilita su coincidencia con el significado del texto de la consulta. Más tarde, la consulta se procesa de manera similar.
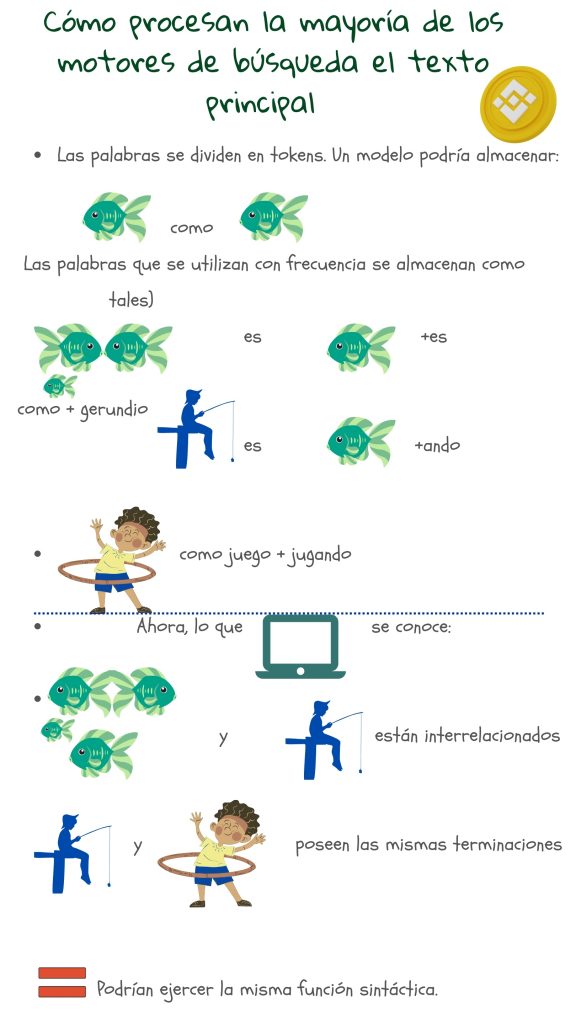
Como partes de una palabra, el número total de identificadores (conocidos en informática como token) diferentes que necesitan ser almacenados se reduce. Los modelos actuales almacenan alrededor de 30,000 a 50,000 tokens2. Las palabras mal escritas pueden ser identificadas porque partes de ellas aun coinciden con los tokens almacenados. Palabras desconocidas pueden arrojar resultados de búsqueda, ya que sus partes podrían coincidir con los tokens almacenados.
Aquí, el conjunto de entrenamiento para el aprendizaje automático está hecho de textos de ejemplo. Comenzando desde caracteres individuales, espacio y puntuación, el modelo fusiona caracteres que se dan con frecuencia, para formar nuevos tokens. Si el número de tokens no es lo suficientemente alto, continúa el proceso de fusión para cubrir partes de palabras más grandes o menos frecuentes. De esta manera, la mayoría de las palabras, finales de palabras y todos los prefijos pueden ser cubiertos. Así, dado un nuevo texto, la máquina puede dividirlo fácilmente en tokens y enviarlo al almacenamiento.
Paso 3: se construye un índice para fácil referencia

Licencia: Creative Commons Atribución-SinObraDerivada 2.0 (CC BY-ND 2.0). https://creativecommons.org/licenses/by-nd/2.0/
Una vez que los datos están guardados en BigTables, se crea un índice. Similar en idea a los índices de libros de texto, el índice de búsqueda lista tokens y su ubicación en un documento web. Las estadísticas muestran cuántas veces ocurre un token en un documento y cuán importante es para el documento, etc., y la información se posiciona así: ¿está el token en el título o un encabezado, está concentrado en una parte del documento y sigue un token siempre a otro?
Hoy en día, muchos motores de búsqueda usan un modelo basado en lenguaje generado por redes neuronales profundas. Este último codifica detalles semánticos del texto y es responsable de una mejor comprensión de las consultas3. Las redes neuronales ayudan a los motores de búsqueda a ir más allá de la consulta, para capturar la necesidad de información que indujo la consulta en primer lugar.
Estos tres pasos dan una cuenta simplificada de lo que se llama «indexación», encontrar, preparar y almacenar documentos y crear el índice. Los pasos involucrados en «clasificación» vienen a continuación: hacer coincidir la consulta con el contenido y mostrar los resultados según la relevancia.
1 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015
2 Sennrich,R., Haddow, B., and Birch, A., Neural Machine Translation of Rare Words with Subword Units, In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics, 2016.
3 Metzler, D., Tay, Y., Bahri, D., & Najork, M. (2021, June). Rethinking search: Making domain experts out of dilettantes[Opinion paper]. SIGIR Forum, 55(1), Article 13. https://doi.org/10.1145/3476415.3476428
