11 Habla de IA: clasificación de motores de búsqueda
En comparación con los motores de búsqueda de principios de los 2000, los motores de búsqueda actuales realizan análisis más ricos y profundos. Por ejemplo, además de contar palabras, pueden analizar y comparar el significado detrás de las palabras1. Gran parte de esta riqueza ocurre en el proceso de clasificación:
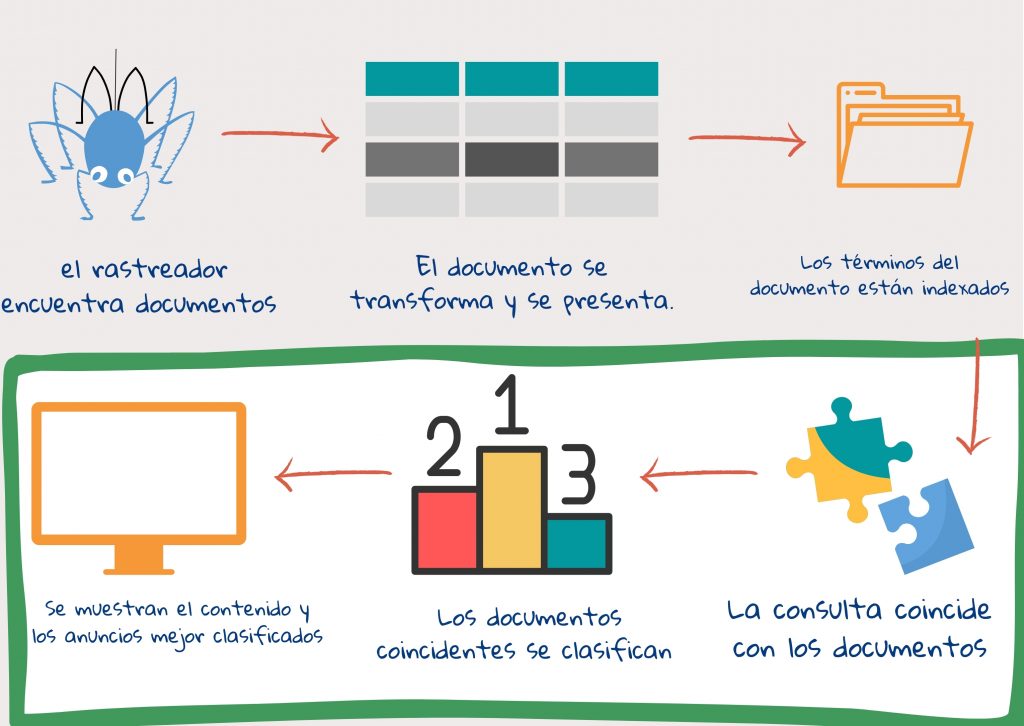
Paso 4: Los términos de consulta se emparejan con términos del índice

Una vez que el usuario escribe la consulta y hace clic en buscar, la consulta se procesa. Se crean tokens usando el mismo proceso que el texto del documento. Luego, la consulta puede expandirse agregando otras palabras clave. Esto es para evitar la situación en la que no se encuentran documentos relevantes porque la consulta usa palabras que son ligeramente diferentes a las de los autores del contenido web. Esto también se hace para capturar diferencias en la costumbre y el uso. Por ejemplo, el uso de palabras como presidente, primer ministro y canciller puede intercambiarse, dependiendo del país1.
La mayoría de los motores de búsqueda mantienen un registro de las búsquedas de los usuarios (Mire la descripción de motores de búsqueda populares para aprender más). Las consultas se registran con los datos del usuario para personalizar el contenido y servir anuncios. O, los registros de todos los usuarios se juntan para ver cómo y dónde mejorar el rendimiento del motor de búsqueda.
Los registros de usuario contienen elementos como consultas pasadas, la página de resultados e información sobre lo que funcionó. Por ejemplo, ¿en qué hizo clic el usuario y qué se tomó su tiempo para leer? Con los registros de usuario, cada consulta se puede emparejar con documentos relevantes (el usuario hace clic, lee y cierra sesión) y documentos no relevantes (el usuario no hizo clic o no leyó o intentó reformular la consulta)2.
Con estos registros, cada nueva consulta se puede emparejar con una consulta pasada similar. Una forma de averiguar si una consulta es similar a otra, es verificar si la clasificación arroja los mismos documentos. Las consultas similares no siempre contienen las mismas palabras, pero los resultados probablemente sean idénticos2.
Se añade ortografía para expandir la consulta. Esto se hace mirando otras palabras que ocurren frecuentemente en documentos relevantes del pasado. En general, sin embargo, las palabras que ocurren más frecuentemente en los documentos relevantes que en los documentos no relevantes se añaden a la consulta o se les da un peso adicional2.
Paso 5: los documentos relevantes se clasifican
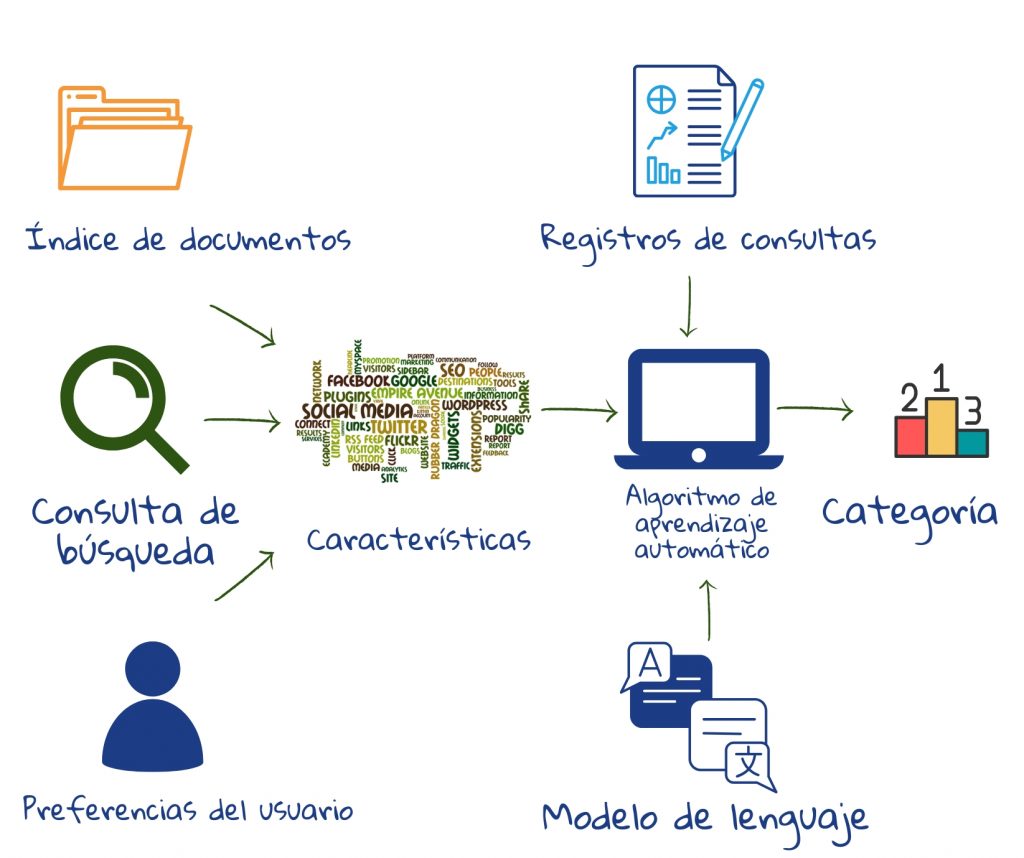
Cada documento se puntúa por relevancia y se clasifica según esta puntuación. La relevancia aquí es tanto la relevancia del tema –cuán bien los términos del índice de un documento coinciden con los de la consulta, como la relevancia para el usuario– cuán bien coincide con las preferencias del usuario. Parte de la puntuación del documento se puede hacer durante la indexación. La velocidad del motor de búsqueda depende de la calidad de los índices. Su efectividad se basa en cómo se empareja la consulta con el documento así como en el sistema de clasificación2.

La relevancia para el usuario se mide creando modelos de usuario (o tipos de personalidad), basados en sus términos de búsqueda anteriores, sitios visitados, mensajes de correo electrónico, el dispositivo que están usando, idioma y ubicación geográfica. Cookies se utilizan para almacenar las preferencias del usuario. Algunos motores de búsqueda también compran información del usuario de terceros (podría referirse a descripciones de algunos motores de búsqueda). Si una persona está interesada en el fútbol, sus resultados para «Manchester» serán diferentes de la persona que acaba de reservar un vuelo a Londres. Las palabras que ocurren frecuentemente en los documentos asociados con una persona se les dará la mayor importancia.
Los motores de búsqueda comerciales incorporan cientos de características en sus algoritmos de clasificación; muchas derivadas de la enorme colección de datos de interacción del usuario en los registros de consultas. Una función de clasificación combina el documento, la consulta y las características de relevancia del usuario. Cualquiera que sea la función de clasificación utilizada, tendría una base matemática sólida. El resultado es la probabilidad de que un documento satisfaga la necesidad de información del usuario. Por encima de cierta probabilidad de relevancia, el documento se clasifica como relevante2.
El aprendizaje automático se utiliza para aprender sobre la clasificación basada en la retroalimentación implícita del usuario en los registros (es decir, lo que funcionó en consultas anteriores). El aprendizaje automático también se ha utilizado para desarrollar modelos sofisticados de cómo los humanos usan el lenguaje; esto se utiliza para descifrar consultas1,2.
Los avances en la búsqueda web han sido extraordinarios en la última década. Sin embargo, cuando se refiere a entender el contexto para una consulta específica, no hay sustituto para que el usuario proporcione una mejor consulta. Típicamente, las mejores consultas provienen de usuarios que examinan resultados y reformulan la consulta2.
Paso 6: se muestran los resultados
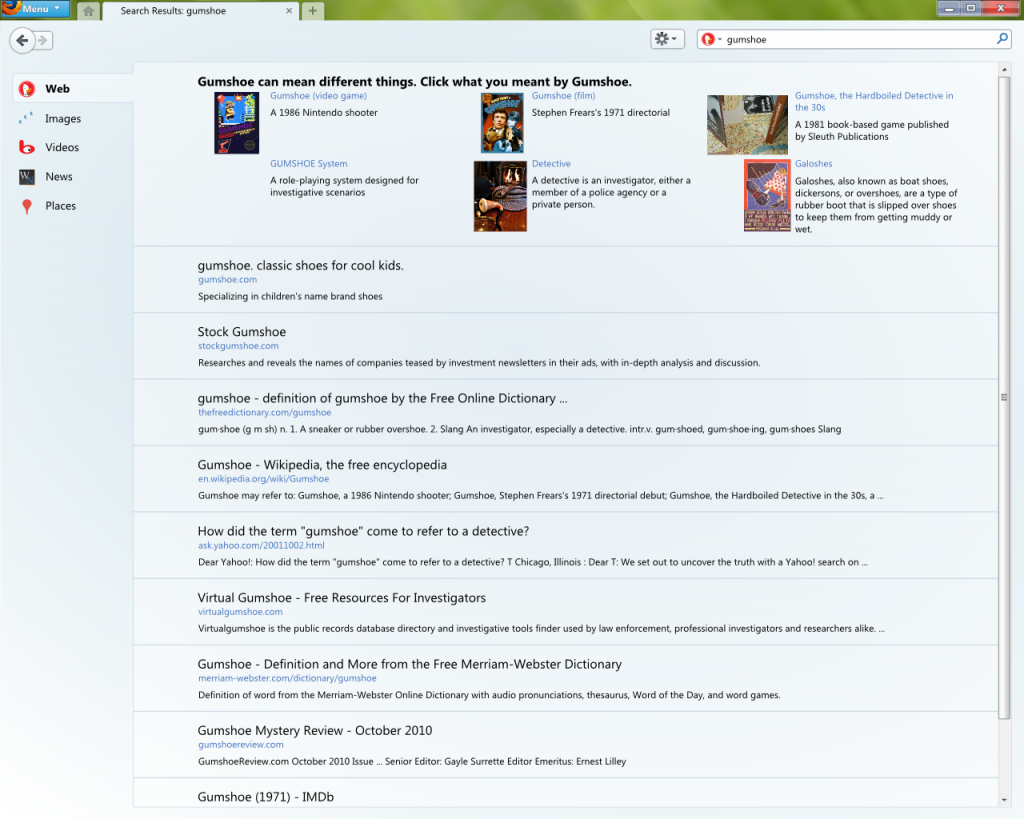
Los resultados están listos. Se muestra el título de la página y la url, con los términos de consulta en negrita. Se genera y muestra un breve resumen después de cada enlace. El resumen destaca pasajes importantes en el documento.
En este sentido, se toman oraciones de encabezados, descripción de metadatos o de texto que mejor corresponde con la consulta. Si todos los términos de consulta aparecen en el título, no se repetirán en el fragmento2. Las oraciones también se seleccionan en función de cuán legibles son.
Se añade publicidad apropiada a los resultados. Los motores de búsqueda generan ingresos a través de anuncios. En algunos motores de búsqueda, están claramente marcados como contenido patrocinado, mientras que en otros no lo están. Dado que muchos usuarios solo miran los primeros resultados, los anuncios pueden cambiar el proceso sustancialmente.
Los anuncios se eligen según el contexto de la consulta y el modelo de usuario. Las compañías de motores de búsqueda mantienen una base de datos de anuncios. Esta base de datos se busca para encontrar los anuncios más relevantes para una consulta dada. Los anunciantes compiten por palabras clave que describen temas asociados con su producto. Tanto el monto de la competencia como la popularidad de un anuncio son factores significativos en el proceso de selección2.
Para preguntas sobre hechos, algunos motores usan su propia colección de hechos. La Bóveda de Conocimiento de Google contiene más de mil millones de hechos indexados de diferentes fuentes3. Los resultados se agrupan por algoritmos de aprendizaje automático en grupos apropiados. Finalmente, al usuario también se le presentan alternativas a la consulta para ver si son mejores.
Algunas referencias
El origen de Google se puede encontrar en el artículo original de Brin y Page. Algunas de las matemáticas detrás de PageRank están en PageRank de Wiki. Para los matemáticamente inclinados, aquí hay una buena explicación de PageRank.
1 Russell, D. M. (2015). What do you need to know to use a search engine? Why we still need to teach research skills. AI Magazine, 36(4), 61–70. https://doi.org/10.1609/aimag.v36i4.2617
2 Croft, W. B., Metzler, D., & Strohman, T. (2015). Search engines: Information retrieval in practice. Pearson. [Versión gratuita disponible en PDF] https://ciir.cs.umass.edu/irbook/
3 Spencer, S. (2021). Google Power Search: The essential guide to finding anything online with Google [Kindle edition]. Koshkonong. https://www.amazon.com/dp/B09BHTN8QB
