29 Habla de IA: redes neuronales profundas
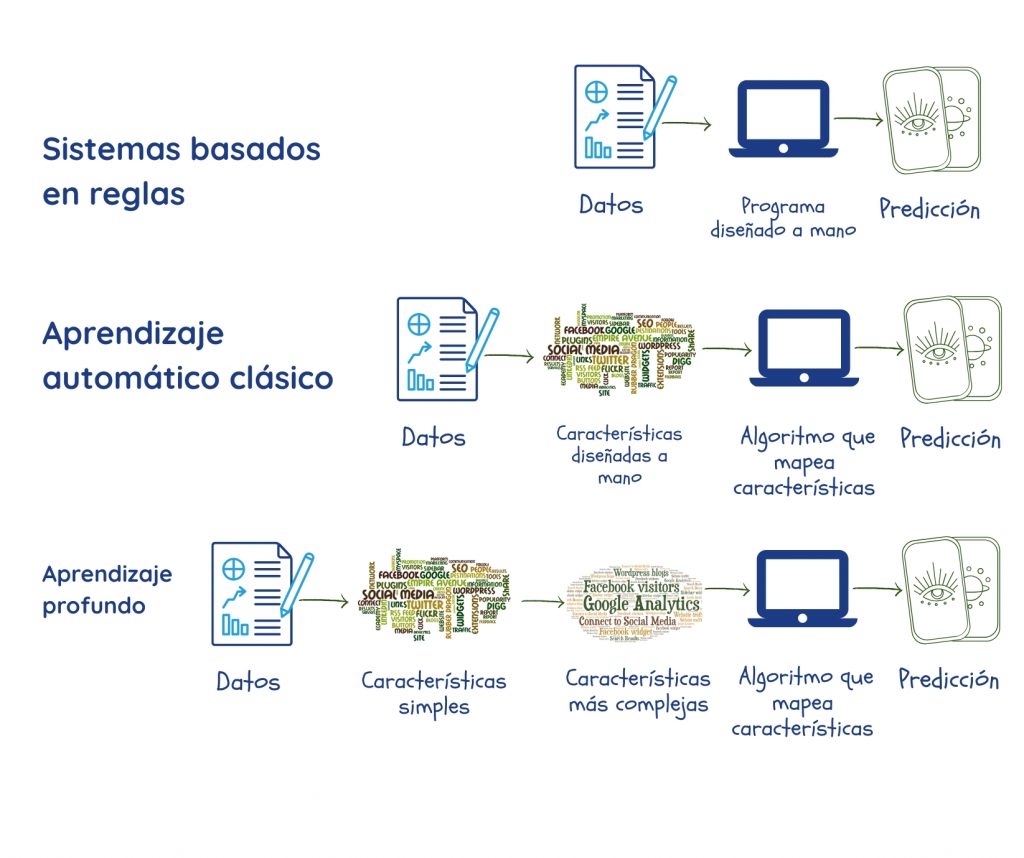
El aprendizaje automático se profundiza
El conocimiento humano es amplio y variable y es inherentemente difícil de capturar. La mente humana puede absorber y trabajar con el conocimiento porque es, como lo puso Chomsky, «un sistema sorprendentemente eficiente e incluso elegante que opera con pequeñas cantidades de información; no busca inferir brutales correlaciones entre puntos de datos sino crear explicaciones1.»
Se supone que el AA lo hace encontrando patrones en grandes cantidades de datos. Pero, antes de eso, expertos y programadores tenían que sentarse y codificar qué características de los datos eran relevantes para el problema en cuestión, y alimentar estas a la máquina como «parámetros»2,3. Como vimos antes, el rendimiento del sistema depende en gran medida de la calidad de los datos y los parámetros, que no siempre son fáciles de precisar.
Las redes neuronales profundas o el aprendizaje profundo es una rama del AA que está diseñado para superar esto mediante:
- Extracción de sus propios parámetros de los datos durante la fase de entrenamiento;
- Usando múltiples capas que construyen relaciones entre los parámetros, avanzando progresivamente desde representaciones simples en la capa más externa hasta más complejas y abstractas. Esto le permite hacer ciertas cosas mejor que los algoritmos convencionales de ML2.
Cada vez más, la mayoría de las aplicaciones poderosas de ML usan aprendizaje profundo. Estas incluyen motores de búsqueda, sistemas de recomendación, transcripción y traducción de voz que hemos cubierto en este libro. No sería exagerado decir que el aprendizaje profundo ha impulsado el éxito de la IA en múltiples tareas.
«Profundo» se refiere a cómo las capas se apilan una encima de otra para crear la red. «Neuronal» refleja el hecho de que algunos aspectos del diseño se inspiraron en el cerebro biológico. A pesar de eso, y aunque proporcionan algunas ideas sobre nuestros propios procesos de pensamiento, estos son modelos estrictamente matemáticos y no se parecen a ninguna parte o proceso biológico2.
Los fundamentos del aprendizaje profundo
Cuando los humanos miramos una imagen, identificamos automáticamente objetos y rostros. Pero una foto es solo una colección de píxeles para un algoritmo. Pasar de un revoltijo de colores y niveles de brillo, a reconocer un rostro, es un salto demasiado complicado para ejecutar.
El aprendizaje profundo logra esto descomponiendo el proceso en representaciones simples en la primera capa, por ejemplo, comparando el brillo de píxeles vecinos para notar la presencia o ausencia de bordes en varias regiones de la imagen. La segunda capa toma colecciones de bordes para buscar entidades más complejas, como esquinas y contornos, ignorando pequeñas variaciones en las posiciones de los bordes2,3. La siguiente capa busca partes de los objetos usando los contornos y esquinas. Lentamente, la complejidad se construye hasta el punto donde la última capa puede combinar diferentes partes lo suficientemente bien como para reconocer un rostro o identificar un objeto.
.
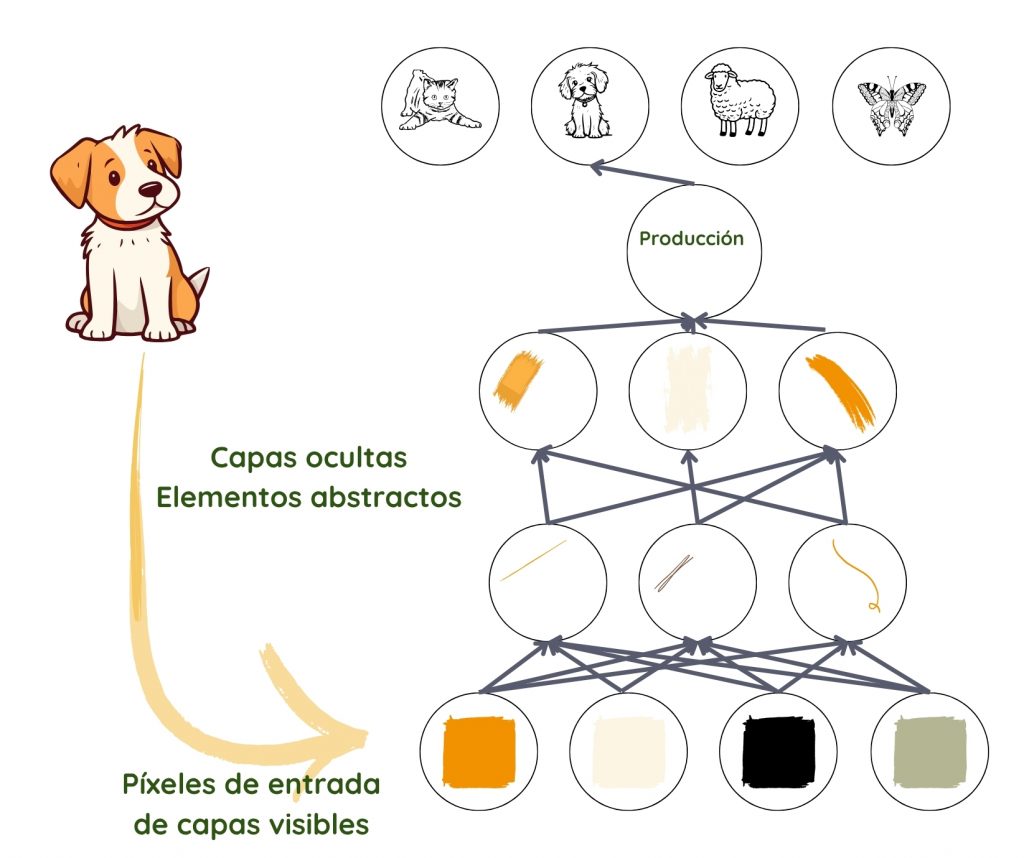
Lo que se debe tener en cuenta en cada capa no lo especifican los programadores, sino que se aprende de los datos en el proceso de entrenamiento3. Al probar estas predicciones con los resultados reales en el conjunto de datos de entrenamiento, el funcionamiento de cada capa se ajusta de manera ligeramente diferente para obtener un mejor resultado cada vez. Cuando se hace correctamente, y siempre que haya datos de buena calidad en cantidad suficiente, la red debería evolucionar para ignorar partes irrelevantes de la foto, como la ubicación exacta de las entidades, el ángulo y la iluminación, y centrarse en aquellas partes que hacen posible el reconocimiento.
Cabe destacar aquí el hecho de que, a pesar de nuestro uso de bordes y contornos para entender el proceso, lo que realmente se representa en las capas es un conjunto de números, que podrían o no corresponder a cosas que entendemos. Lo que no cambia es la creciente abstracción y complejidad.
Diseñando la red
Una vez que el programador decide usar el aprendizaje profundo para una tarea y prepara los datos, tiene que diseñar lo que se llama la arquitectura de su red neuronal. Tienen que elegir el número de capas (profundidad de la red) y el número de parámetros por capa (ancho de la red). A continuación, tienen que decidir cómo hacer conexiones entre las capas, si cada unidad de una capa estuviera conectada o no a cada unidad de la capa anterior.
La arquitectura ideal para una tarea dada se encuentra a menudo por experimentación. Cuanto mayor es el número de capas, menos parámetros se necesitan por capa y la red funciona mejor con datos generales, a costa de ser difícil de optimizar. Menos conexiones significarían menos parámetros, y menor cantidad de cálculo, pero reduce la flexibilidad de la red2.
Entrenando la red
Tomemos el ejemplo de una red neuronal de avance directo haciendo aprendizaje supervisado. Aquí, la información fluye hacia adelante de capa a capa más profunda, sin bucles de retroalimentación. Como en todas las técnicas de AA, el objetivo aquí es descubrir cómo la entrada está conectada a la salida, qué parámetros se unen, y cómo se unen para dar el resultado observado. Asumimos una relación f que conecta la entrada x con la salida y. Luego usamos la red para encontrar el conjunto de parámetros θ que dan la mejor coincidencia para las salidas predichas y reales.
Pregunta clave: La y predicha es f (x, θ), ¿para qué θ?
Aquí la predicción para y es el producto final y el conjunto de datos x es la entrada. En el reconocimiento facial, x suele ser el conjunto de píxeles en una imagen. y puede ser el nombre de la persona. En la red, las capas son como trabajadores en una línea de ensamblaje, donde cada trabajador trabaja en lo que se les da y lo pasa hacia adelante al siguiente trabajador. El primero toma la entrada y la transforma un poco y se la da al segundo en línea. El segundo hace lo mismo antes de pasárselo al tercero, y así sucesivamente hasta que la entrada se transforma en el producto final.
Matemáticamente, la función f se divide en muchas funciones f1, f2, f3… donde f= ….f3(f2(f1(x))). La capa junto a la entrada transforma los parámetros de entrada usando f1, la siguiente capa usando f2, y así sucesivamente. El programador podría intervenir para ayudar a elegir la familia correcta de funciones basada en su conocimiento del problema.
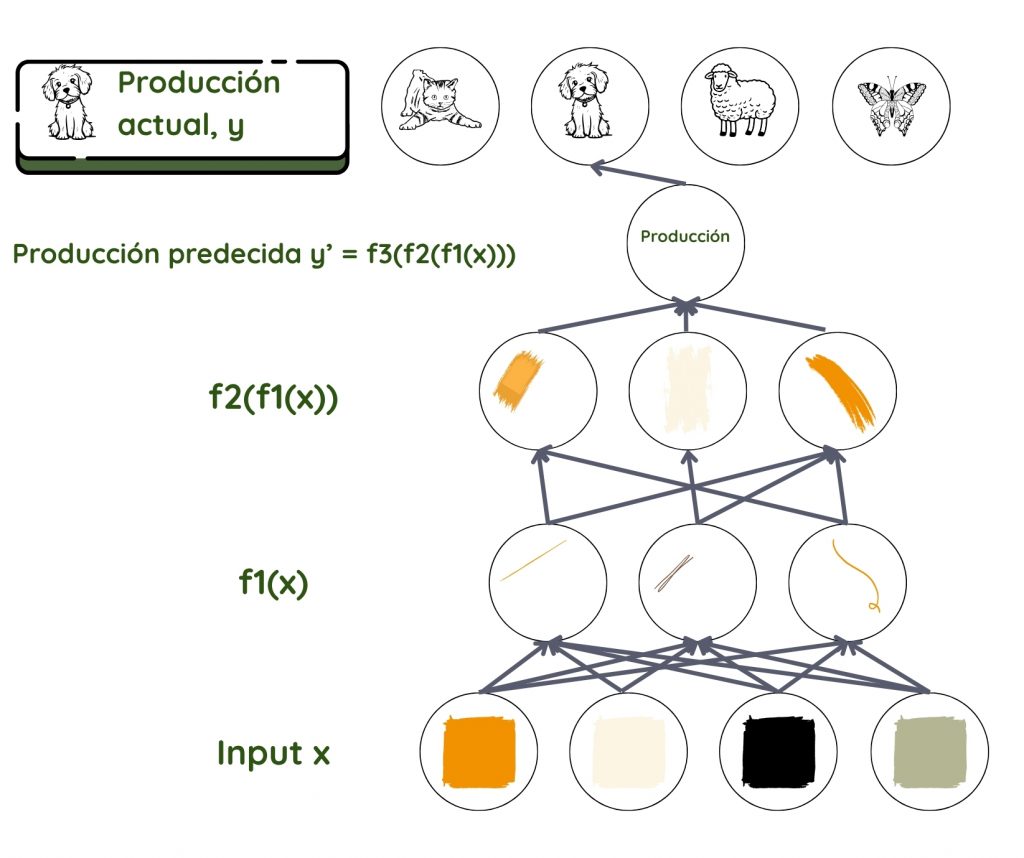
Es el trabajo de cada capa asignar el nivel de importancia, el peso dado a cada parámetro que recibe. Estos pesos son como perillas que en última instancia definen la relación entre la salida predicha y la entrada en esa capa3. En un sistema típico de aprendizaje profundo, estamos viendo cientos de millones de estas perillas y cientos de millones de ejemplos de entrenamiento. Dado que ni definimos ni podemos ver la salida y los pesos en las capas entre la entrada y la salida, estas se llaman capas ocultas.
En el caso del ejemplo de reconocimiento de objetos discutido anteriormente, es el trabajo del primer trabajador detectar bordes y pasar los bordes al segundo que detecta contornos y así sucesivamente.
Durante el entrenamiento, la salida predicha se toma y se compara con la salida real. Si hay una gran diferencia entre las dos, los pesos asignados en cada capa tendrán que cambiarse mucho. Si no, tienen que cambiarse un poco. Este trabajo se hace en dos partes. Primero se calcula la diferencia entre la predicción y la salida. Luego otro algoritmo calcula cómo cambiar los pesos en cada capa, comenzando desde la capa de salida (en este caso, la información fluye hacia atrás desde las capas más profundas). Así al final del proceso de entrenamiento, la red está lista con sus pesos y funciones para atacar los datos de prueba. El resto del proceso es el mismo que el del AA convencional.
1 Chomsky, N., Roberts, I., & Watumull, J. (2023). Noam Chomsky: The false promise of ChatGPT. The New York Times. https://www.nytimes.com/2023/03/08/opinion/noam-chomsky-chatgpt-ai.html
2 Goodfellow, I. J., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press. http://www.deeplearningbook.org/
3 LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444. https://doi.org/10.1038/nature14539
