19 Problemas con los datos: sesgo y equidad
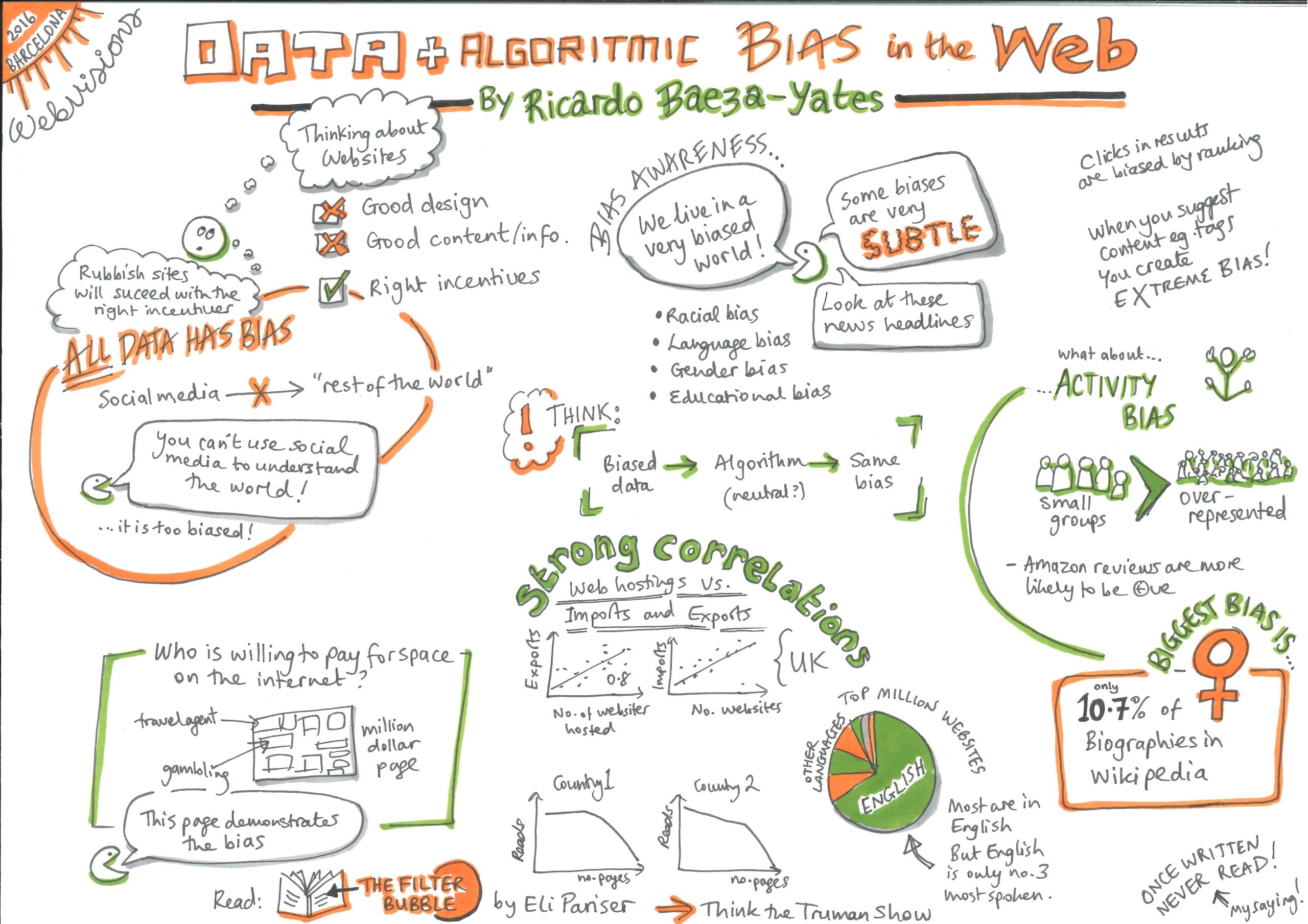
El sesgo es un prejuicio hacia o en contra de una identidad, ya sea bueno o malo, intencional o no intencional1. La equidad es la contraparte de este sesgo y más: cuando todos son tratados de manera justa, independientemente de su identidad y situación. Se deben establecer y seguir procesos claros para asegurarse de que todos sean tratados de manera equitativa y tengan igual acceso a las oportunidades1.
Los sistemas basados en humanos a menudo comprenden mucho sesgo y discriminación. Cada persona tiene su propio conjunto único de opiniones y prejuicios. Ellos también son cajas negras cuyas decisiones, como la forma en que califican las hojas de respuestas, pueden ser difíciles de entender. Pero hemos desarrollado estrategias y establecido estructuras para estar atentos y cuestionar tales prácticas.
Los sistemas automatizados a veces se promocionan como la panacea para la subjetividad humana: los algoritmos se basan en números, ¿cómo pueden tener sesgos? Los algoritmos basados en datos defectuosos, entre otras cosas, no solo pueden recoger y aprender los sesgos existentes relacionados con el género, la raza, la cultura o la discapacidad, sino que pueden amplificar los sesgos existentes1,2,3. Incluso si no están protegidos por muros propietarios, no se les puede pedir que expliquen sus acciones debido a la falta inherente de explicabilidad en algunos sistemas, como aquellos basados en Redes Neuronales Profundas.
Ejemplos de cómo el sesgo entra en los sistemas AIED
- Cuando los programadores codifican sistemas basados en reglas, pueden introducir sus sesgos y estereotipos personales en el sistema1;
- Un algoritmo basado en datos puede concluir no proponer una carrera basada en STEM para las niñas, porque las estudiantes femeninas aparecen menos en el conjunto de datos de graduados en STEM. ¿Es el menor número de matemáticas de género femenino debido a estereotipos existentes y normas sociales o se debe a alguna propiedad inherente de ser mujer? Los algoritmos no tienen forma de distinguir entre las dos situaciones. Dado que los datos existentes reflejan estereotipos existentes, los algoritmos que se entrenan con ellos replican desigualdades existentes y dinámicas sociales4. Además, si tales recomendaciones se implementan, más niñas optarán por materias no STEM y los nuevos datos reflejarán esto, un caso de profecía autocumplida3.
- Los estudiantes de una cultura subrepresentada en el conjunto de datos de entrenamiento podrían tener diferentes patrones de comportamiento y diferentes formas de mostrar motivación. ¿Cómo calcularía una analítica de aprendizaje las métricas para ellos? Si los datos no son representativos de todas las categorías de estudiantes, los sistemas entrenados con estos datos podrían penalizar a la minoría cuyas tendencias de comportamiento no son lo que el programa estaba optimizado para recompensar. Si no tenemos cuidado, los algoritmos de aprendizaje generalizarán, basándose en la cultura mayoritaria, lo que lleva a una alta tasa de error para los grupos minoritarios4,5. Tales decisiones podrían desalentar a aquellos que podrían aportar diversidad, creatividad y talentos únicos y aquellos que tienen diferentes experiencias, intereses y motivaciones2;
- Un estudiante británico juzgado por un software de corrección de ensayos de EEUU sería penalizado por sus errores de ortografía. El lenguaje local, los cambios en la ortografía y el acento, la geografía y la cultura locales, siempre serán complicados para sistemas que están diseñados y entrenados para otro país y otro contexto.
- Algunos profesores penalizan frases comunes a una clase o región, ya sea consciente o debido a asociaciones sociales sesgadas. Si un software de calificación de ensayos se entrena con ensayos calificados por estos profesores, replicará el mismo sesgo.
- Los sistemas de aprendizaje automático necesitan una variable objetivo y proxies para optimizar. Digamos que las calificaciones de los exámenes de secundaria se tomaron como el proxy para la excelencia académica. El sistema ahora se entrenará exclusivamente para impulsar patrones que son consistentes con los estudiantes que se desempeñan bien bajo el estrés y los contextos limitados de las aulas de examen. Tales sistemas impulsarán las calificaciones de los exámenes, y no el conocimiento, al recomendar recursos y ejercicios de práctica a los estudiantes. Aunque esto también puede ser cierto en muchas de las aulas de hoy, el enfoque tradicional al menos hace posible expresar múltiples objetivos4.
- Los sistemas de aprendizaje adaptativo sugieren recursos a los estudiantes que resolverán una falta de habilidad o conocimiento. Si estos recursos necesitan ser comprados o requieren conexión a internet en casa, entonces no es justo para aquellos estudiantes que no tienen los medios para seguir las recomendaciones: «Cuando un algoritmo sugiere pistas, próximos pasos o recursos a un estudiante, tenemos que verificar si la ayuda es injusta porque un grupo sistemáticamente no recibe ayuda útil, lo cual es discriminatorio«2.
- El concepto de personalizar la educación según el nivel de conocimiento actual y los gustos de un estudiante podría en sí mismo constituir un sesgo1. ¿No estamos también impidiendo que este estudiante explore nuevos intereses y alternativas? ¿No lo haría esto unidimensional y reduciría las habilidades generales, el conocimiento y el acceso a oportunidades?
¿Qué puede hacer el maestro para reducir los efectos de los sesgos AIED?
Los investigadores están proponiendo y analizando constantemente diferentes formas de reducir el sesgo. Pero no todos los métodos son fáciles de implementar: la equidad va más allá de mitigar el sesgo.
Por ejemplo, si los datos existentes están llenos de estereotipos: «¿tenemos la obligación de cuestionar los datos y diseñar nuestros sistemas para que se ajusten a alguna noción de comportamiento equitativo, independientemente de si eso está respaldado o no por los datos actualmente disponibles para nosotros?«4. Los métodos siempre están en tensión y oposición entre sí y algunas intervenciones para reducir un tipo de sesgo pueden introducir otro sesgo.
Entonces, ¿qué puede hacer el maestro?
- Cuestionar al vendedor. Antes de suscribirse a un sistema AIED, pregunte qué tipo de conjuntos de datos se usaron para entrenarlo, dónde, por y para quién fue concebido y diseñado, y cómo fue evaluado;
- No tragar las métricas cuando invierta en un sistema AIED. Una precisión general, digamos, del cinco por ciento, podría ocultar el hecho de que un modelo funciona mal para un grupo minoritario4;
- Mirar la documentación ¿qué medidas, si las hay, se han tomado para detectar y contrarrestar el sesgo y hacer cumplir la equidad1?;
- Informarse sobre los desarrolladores ¿son exclusivamente expertos en informática o participaron investigadores en educación y profesores? ¿El sistema se basa únicamente en el aprendizaje automático o se integraron la teoría y las prácticas de aprendizaje2?
- Dar preferencia a modelos de aprendizaje abiertos y transparentes que le permitan anular decisiones2 Muchos modelos AIED tienen diseños flexibles mediante los cuales el maestro y el estudiante pueden monitorear el sistema, pedir explicaciones o ignorar las decisiones de la máquina.
- Examinar la accesibilidad del producto. ¿Pueden todos acceder a él por igual, independientemente de su capacidad1?
- Estar atento a los efectos de usar una tecnología, tanto a largo como a corto plazo, en los estudiantes, y estar listo para ofrecer asistencia cuando sea necesario.
A pesar de los problemas de la tecnología basada en IA, podemos ser optimistas sobre el futuro de AIED:
- Con una mayor conciencia de estos temas, se están investigando y probando métodos para detectar y corregir el sesgo;
- Los sistemas basados en reglas y datos pueden descubrir sesgos ocultos en las prácticas educativas existentes. Expuestos así, estos sesgos pueden ser abordados;
- Con el potencial de personalización en los sistemas de IA, muchos aspectos de la educación podrían ser adaptados. Los recursos podrían volverse más receptivos al conocimiento y la experiencia de los estudiantes. Quizás podrían integrar comunidades locales y activos culturales, y satisfacer necesidades locales específicas2.
1 European Commission. (2022, October). Ethical guidelines on the use of artificial intelligence and data in teaching and learning for educators. Publications Office of the European Union. https://education.ec.europa.eu/document/ethical-guidelines-on-the-use-of-ai-and-data-in-teaching-and-learning-for-educators
2 U.S. Department of Education, Office of Educational Technology. (2023). Artificial Intelligence and Future of Teaching and Learning: Insights and Recommendations. Washington, DC. https://tech.ed.gov/ai-future-of-teaching-and-learning/
3 Kelleher, J. D., & Tierney, B. (2018). Data science. MIT Press. https://mitpress.mit.edu/9780262535434/data-science/
4 Barocas, S., Hardt, M., & Narayanan, A. (2023). Fairness and machine learning: Limitations and opportunities. MIT Press. https://fairmlbook.org/
5 Milano, S., Taddeo, M., & Floridi, L. (2020). Recommender systems and their ethical challenges. AI & Society, 35(6), 957–967. https://doi.org/10.1007/s00146-020-00950-y
