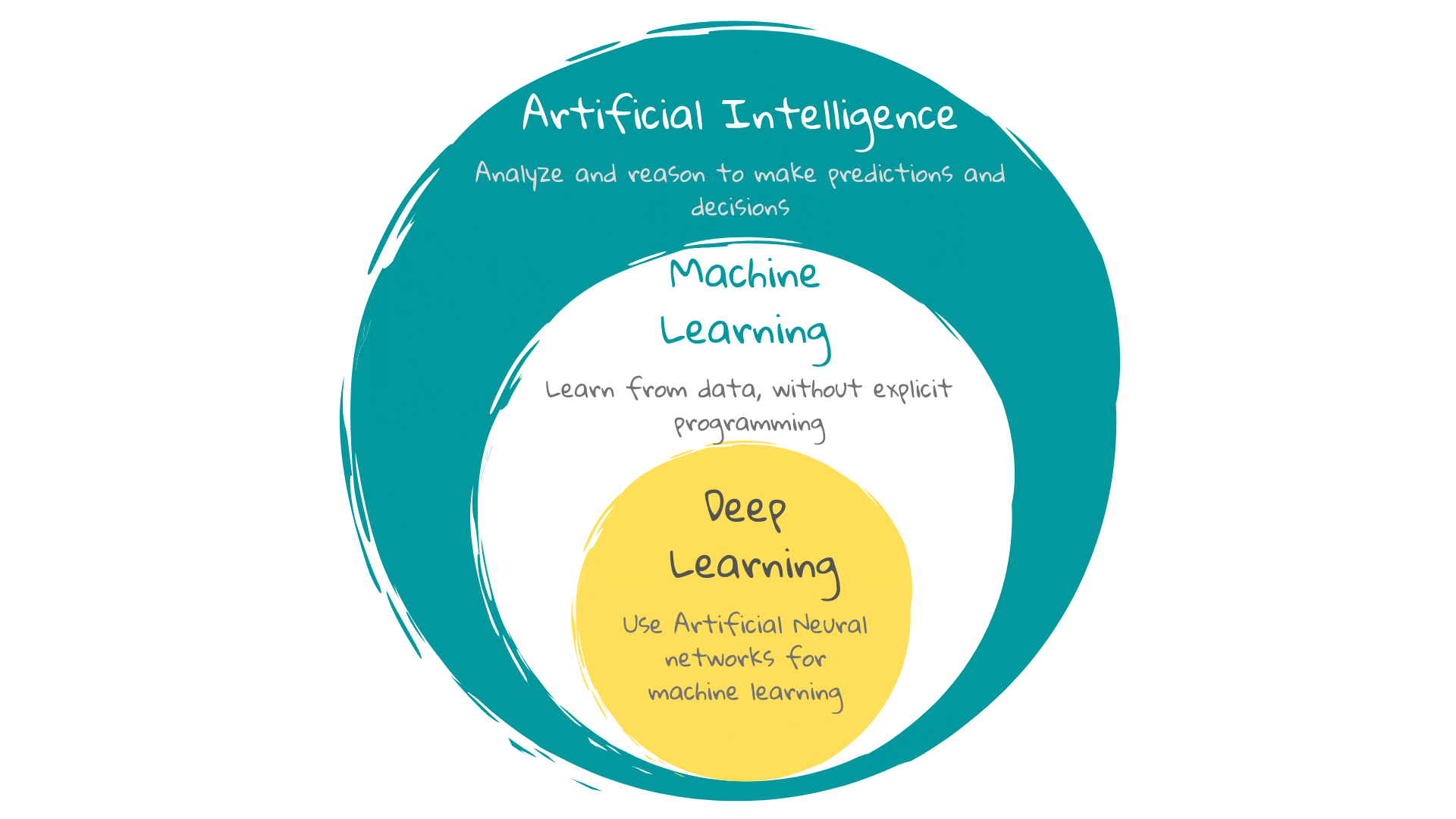
9
An algorithm is a fixed sequence of instructions for carrying out a task. It breaks down the task into easy, confusion-free steps, like a well written recipe.
Programming languages are languages that a computer can follow and execute. They act as a bridge between what we and a machine can understand. Ultimately, these are switches that go on and off. For a computer , images, videos, instructions are all 1s (switch is on) and 0s (switch is off).
When written in a programming language, an algorithm becomes a program. Applications are programs written for an end user.
Conventional programs take in data and follow the instructions to give an output. Many early AI programs were conventional. Since the instructions cannot adapt to the data, these programs were not very good at things like predicting based on incomplete information and natural language processing (NLP).
 A search engine is powered by both conventional and Machine learning algorithms. As opposed to conventional programs, ML algorithms analyse data for patterns and use these patterns or rules to make future decisions or predictions. So, based on data, good and bad examples, they find their own recipe.
A search engine is powered by both conventional and Machine learning algorithms. As opposed to conventional programs, ML algorithms analyse data for patterns and use these patterns or rules to make future decisions or predictions. So, based on data, good and bad examples, they find their own recipe.
These algorithms are well suited for situations with a lot of complexity and missing data. They can also monitor their own performance and use this feedback to become better.
This is not too different from humans, especially when we see babies learning skills outside the conventional educational system. Babies observe, repeat, learn, test their learning and improve. Where necessary, they improvise.
But the similarity between machines and humans is shallow. “Learning” from a human perspective is different, and way more nuanced and complex than “learning” for the machine.
A classification problem

One common task a ML application is used to perform is classification – is this a photo of a dog or a cat? Is this student struggling or will they pass the exam? There are two or more groups, and the application has to classify new data into one of them.
Let us take the example of a pack of playing cards – group A and group B – divided into two piles and following some pattern. We need to classify a new card, the ace of diamonds, as belonging to either group A or group B.
First, we need to understand how the groups are split – we need examples. Let us draw four cards from group A and four from group B. These eight example cases form our training set – data which helps us see the pattern – “training” us to see the result.
As soon as we are shown the arrangement to the right, most of us would guess that the ace of diamonds belongs to Group B. We do not need instructions, because the human brain is a pattern-finding marvel. How would a machine do this?
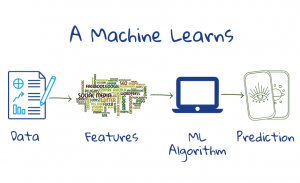
ML algorithms are built on powerful statistical theories. Different algorithms are based on different mathematical equations that have to be chosen carefully to fit the task at hand. It is the job of the programmer to choose the data, analyse what features of the data are relevant to the particular problem and choose the correct ML algorithm.
The importance of data

The card-draw above could have gone wrong in a number of ways. Please refer to the image. 1 has too few cards, no guess would be possible. 2 has more cards but all of the same suit – no way to know where diamonds would go. If the groups were not of the same size, 3 could very well mean that number cards are in group A and picture cards in group B.
Usually machine learning problems are more open ended and involve data sets much bigger than a pack of cards. Training sets have to be chosen with the help of statistical analysis, or else errors creep in. Good data selection is crucial to a good ML application, more so than other types of programs. Machine learning needs a great number of relevant data. At an absolute minimum, a basic machine-learning model should contain ten times as many data points as the total number of features1. That said, ML is also particularly equipped to handle noisy, messy and contradictory data.
Feature Extraction
When shown Group A and Group B examples above, the first thing you might have noticed could be the colour of the cards. Then the number or letter and the suit. For an algorithm, all these features have to be entered specifically. It cannot automatically know what is important to the problem.
While selecting the features of interest, programmers have to ask themselves many questions. How many features are too few to be useful? How many features are too many? Which features are relevant for the task? What is the relationship between the chosen features – is one feature dependent on the other? With the chosen features, is it possible for the output to be accurate?
The process
WhenWhen the programmer is creating the application, they take data, extract features from it, choose an appropriate machine-learning algorithm (mathematical function which defines the process), and train it using labelled data (in the case where the output is known – like group A or group B) so that the machine understands the pattern behind the problem.
For a machine, understanding takes the form of a set of numbers – weights – that it assigns to each feature. With the correct assignment of weights, it can calculate the probability of a new card being in group A or group B. Typically, during the training stage, the programmer helps the machine by manually changing some values. This is called tuning the application.
Once this is done, the program has to be tested before being put to use. For this, the labelled data that was not used for training would be given to the program. This is called the test data. The machine’s performance in predicting the output would then be gauged. Once determined to be satisfactory, the program can be put to use – it is ready to take new data and make a decision or prediction based on this data.
 Can a model function differently on training and test datasets? How does the number of features affect performance on both? Watch this video to find out.
Can a model function differently on training and test datasets? How does the number of features affect performance on both? Watch this video to find out.
The real-time performance is then continuously monitored and improved (feature weights are adjusted to get better output). Often, real-time performance gives different results than when ML is tested with already available data. Since experimenting with real users is expensive, takes a lot of effort, and is often risky, algorithms are always tested using historic user data, which may not be able to assess impact on user behaviour1. This is why it is important to do a comprehensive evaluation of machine learning applications, once in use:
Feel like doing some hands on Machine Learning? Try this activity.
1 Theobald, O. Machine Learning For Absolute Beginners: A Plain English Introduction (Second Edition) (Machine Learning From Scratch Book 1) (p. 24). Scatterplot Press. Kindle Edition.
2 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021.

.jpg){kind=link}