11
Im Vergleich zu den Suchmaschinen der frühen 2000er Jahre führen die heutigen Suchmaschinen umfangreichere und tiefere Analysen durch. Zum Beispiel können sie nicht nur Wörter zählen, sondern auch die Bedeutung hinter den Wörtern analysieren und vergleichen.1 Vieles davon geschieht im Ranking-Prozess:
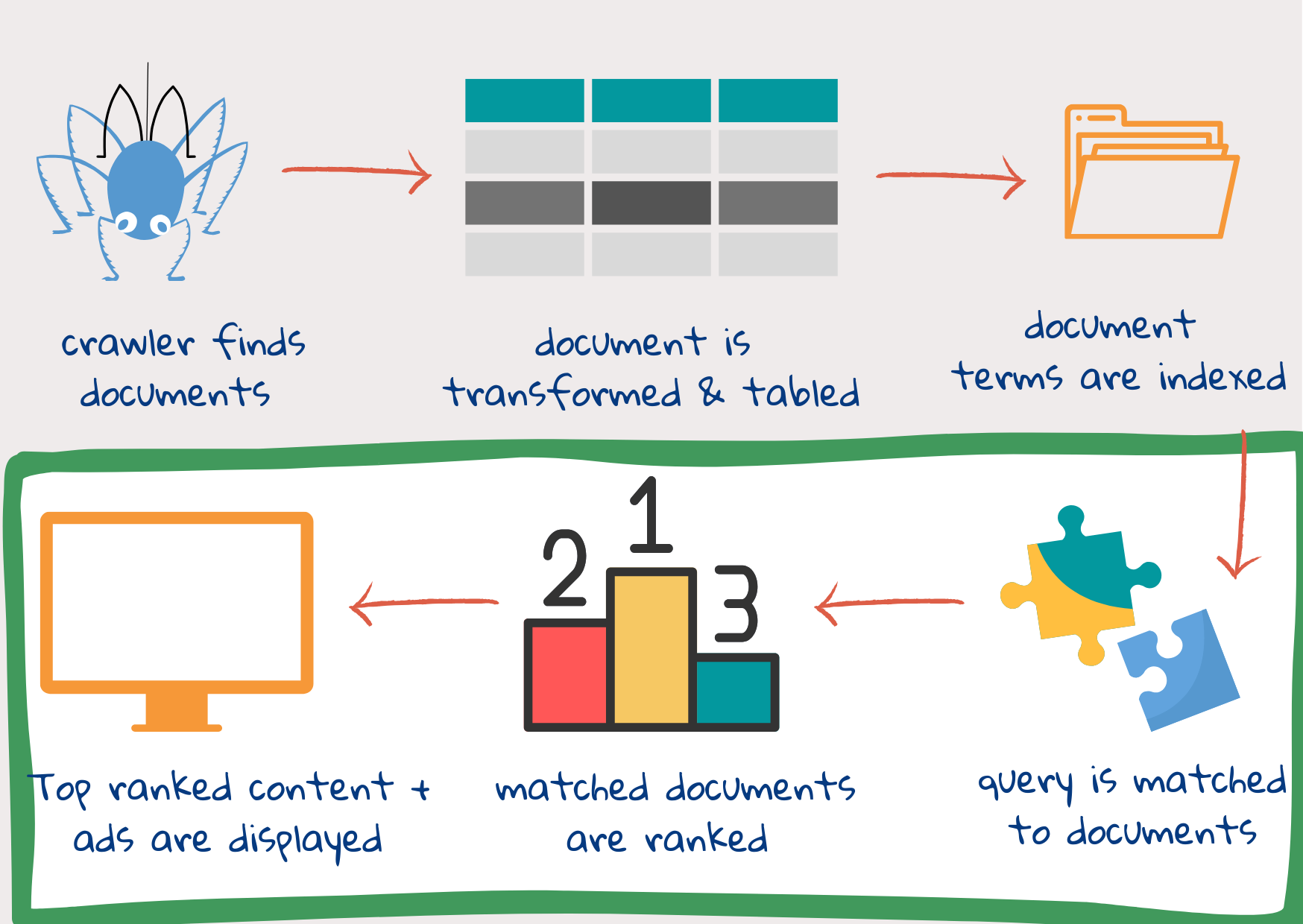
Schritt 4: Abfragebegriffe werden mit Indexbegriffen abgeglichen

Wenn die nutzende Person die Suchanfrage eingibt und auf Suchen klickt, wird die Anfrage verarbeitet. Die Token werden mit demselben Verfahren wie der Dokumententext erstellt. Dann kann die Abfrage durch Hinzufügen weiterer Schlüsselwörter erweitert werden. Damit soll vermieden werden, dass relevante Dokumente nicht gefunden werden, weil die Abfrage etwas andere Wörter verwendet als die Autoren oder Autorinnen der Webinhalte. Dies geschieht auch, um Unterschiede in der Gewohnheit und im Gebrauch zu erfassen. Zum Beispiel kann die Verwendung von Wörtern wie Präsident, Premierminister und Kanzler je nach Land unterschiedlich sein1.
Die meisten Suchmaschinen zeichnen die Suchanfragen der Nutzenden auf (siehe Beschreibung einiger populärer Suchmaschinen). Die Suchanfragen werden zusammen mit den Nutzerdaten aufgezeichnet, um Inhalte zu personalisieren und Werbung zu schalten. Oder die Datensätze aller Nutzenden werden zusammengeführt, um zu sehen, wie und wo die Leistung der Suchmaschine verbessert werden kann.
Benutzerprotokolle enthalten frühere Abfragen, die Ergebnisseite und Informationen darüber, was funktioniert hat — was die nutzende Person angeklickt und was sie gelesen hat. Anhand der Benutzerprotokolle kann jede Abfrage mit relevanten Dokumenten (die nutzende Person klickt, liest und schließt die Sitzung) und nicht relevanten Dokumenten (die nutzende Person hat nicht geklickt oder nicht gelesen oder versucht, die Abfrage neu zu formulieren) abgeglichen werden2.
Anhand dieser Protokolle kann jede neue Abfrage mit einer früheren, ähnlichen Abfrage abgeglichen werden. Eine Möglichkeit, um festzustellen, ob eine Abfrage einer anderen ähnlich ist, besteht darin, zu sehen, ob das Ranking die gleichen Dokumente ergibt: Ähnliche Abfragen enthalten zwar nicht immer die gleichen Wörter, aber die Ergebnisse sind wahrscheinlich identisch2.
Rechtschreibfehler können mit ähnlichen Suchanfragen korrigiert werden. Neue Schlüsselwörter und Synonyme können hinzugefügt werden, um die Abfrage zu erweitern. Im Allgemeinen werden Wörter, die in den relevanten Dokumenten häufiger vorkommen als in den nicht relevanten Dokumenten, der Abfrage hinzugefügt oder zusätzlich gewichtet2.
Schritt 5: Relevante Dokumente werden eingestuft
Jedes Dokument wird nach seiner Relevanz bewertet und entsprechend dieser Bewertung eingestuft. Relevanz bedeutet hier sowohl Themenrelevanz — wie gut die Indexbegriffe eines Dokuments mit denen der Anfrage übereinstimmen — als auch Benutzerrelevanz — wie gut es den Präferenzen der nutzenden Person entspricht. Ein Teil der Dokumentenbewertung kann während der Indizierung erfolgen. Die Geschwindigkeit der Suchmaschine hängt von der Qualität der Indizes ab. Die Effektivität der Suchmaschine hängt davon ab, wie gut die Anfrage mit dem Dokument übereinstimmt und wie das Ranking-System funktioniert2.
 Die Relevanz der Nutzenden wird durch die Erstellung von Nutzermodellen (oder Persönlichkeitstypen) auf der Grundlage ihrer früheren Suchbegriffe, besuchten Websites, E-Mail-Nachrichten, des von ihnen verwendeten Geräts, der Sprache und des geografischen Standorts gemessen. Cookies werden verwendet, um Benutzereinstellungen zu speichern. Einige Suchmaschinen kaufen auch Benutzerinformationen von Dritten (siehe Beschreibung einiger Suchmaschinen). Wenn sich eine Person für Fußball interessiert, werden ihre Ergebnisse für „Manchester” andere sein als die einer Person, die gerade einen Flug nach London gebucht hat. Wörter, die in den Dokumenten, die mit einer Person in Verbindung stehen, häufig vorkommen, erhalten die größte Bedeutung.
Die Relevanz der Nutzenden wird durch die Erstellung von Nutzermodellen (oder Persönlichkeitstypen) auf der Grundlage ihrer früheren Suchbegriffe, besuchten Websites, E-Mail-Nachrichten, des von ihnen verwendeten Geräts, der Sprache und des geografischen Standorts gemessen. Cookies werden verwendet, um Benutzereinstellungen zu speichern. Einige Suchmaschinen kaufen auch Benutzerinformationen von Dritten (siehe Beschreibung einiger Suchmaschinen). Wenn sich eine Person für Fußball interessiert, werden ihre Ergebnisse für „Manchester” andere sein als die einer Person, die gerade einen Flug nach London gebucht hat. Wörter, die in den Dokumenten, die mit einer Person in Verbindung stehen, häufig vorkommen, erhalten die größte Bedeutung.
Kommerzielle Web-Suchmaschinen integrieren Hunderte von Merkmalen in ihre Ranking-Algorithmen, von denen viele aus der riesigen Sammlung von Benutzerinteraktionsdaten in den Abfrageprotokollen stammen. Eine Ranking-Funktion kombiniert das Dokument, die Abfrage und die Relevanzmerkmale der nutzenden Person, und zwar auf einer soliden mathematischen Grundlage. Die Ausgabe ist die Wahrscheinlichkeit, dass ein Dokument den Informationsbedarf der nutzenden Person befriedigt. Ab einer bestimmten Relevanzwahrscheinlichkeit wird das Dokument als relevant eingestuft.2
Maschinelles Lernen wird verwendet, um die Einstufung anhand von implizitem Benutzerfeedback in den Protokollen zu erlernen (was bei früheren Abfragen funktioniert hat). Maschinelles Lernen wurde auch verwendet, um ausgefeilte Modelle zu entwickeln, die zeigen, wie Menschen Sprache verwenden, um Abfragen zu entschlüsseln1, 2. 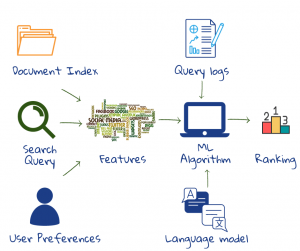
Die Fortschritte bei der Websuche waren im letzten Jahrzehnt phänomenal. Wenn es jedoch darum geht, den Kontext einer bestimmten Anfrage zu verstehen, gibt es keinen Ersatz für eine bessere Anfrage durch die Nutzenden. Bessere Abfragen entstehen in der Regel dadurch, dass die Nutzenden die Ergebnisse prüfen und die Abfrage neu formulieren2.
Schritt 6: Ergebnisse werden angezeigt
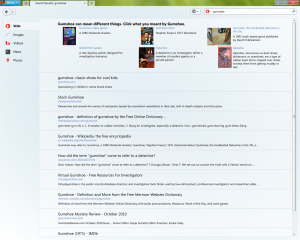
Endlich sind die Ergebnisse bereit, angezeigt zu werden. Der Titel und die URL der Seite werden angezeigt, wobei die Suchbegriffe fett gedruckt sind. Eine kurze Zusammenfassung wird erstellt und nach jedem Link angezeigt. Die Zusammenfassung hebt wichtige Passagen des Dokuments hervor. Hierfür werden Sätze aus Überschriften, Metadatenbeschreibungen oder aus dem Text verwendet, der am besten mit der Abfrage übereinstimmt. Wenn alle Abfragebegriffe im Titel vorkommen, werden sie im Snippet nicht wiederholt2. Die Sätze werden auch danach ausgewählt, wie lesbar sie sind.
Angemessene Werbung wird zu den Ergebnissen hinzugefügt. Mit Werbung erzielen die meisten Suchmaschinen ihre Einnahmen. Bei einigen Suchmaschinen sind sie deutlich als gesponserte Inhalte gekennzeichnet, bei anderen nicht. Da sich viele Nutzende nur die ersten paar Ergebnisse ansehen, verändern Anzeigen den gesamten Prozess erheblich.
Anzeigen werden je nach Kontext der Suchanfrage und dem Nutzermodell ausgewählt. Suchmaschinenunternehmen unterhalten eine Datenbank mit Anzeigen, die durchsucht wird, um die relevantesten Anzeigen für eine bestimmte Suchanfrage zu finden. Die Inserierenden bieten für Schlüsselwörter, die Themen beschreiben, die mit ihrem Produkt in Verbindung stehen. Bei der Auswahl der Anzeigen spielen sowohl der gebotene Betrag als auch die Popularität der Anzeige eine wichtige Rolle2.
Für Fragen zu Fakten verwenden einige Suchmaschinen ihre eigene Sammlung von Fakten. Googles Knowledge Vault enthält über eine Milliarde Fakten aus verschiedenen Quellen.3 Die Ergebnisse werden von Algorithmen für maschinelles Lernen in geeignete Gruppen eingeteilt. Schließlich werden den Nutzenden auch Alternativen zur Abfrage präsentiert, um zu sehen, ob diese besser zu ihrem tatsächlichen Bedarf passen.
Einige Referenzen:
Den Ursprung von Google finden Sie in Brin und Paiges Originalarbeit. Einige der mathematischen Grundlagen von Pagerank finden Sie im Wiki-Artikel PageRank. Mathematisch Interessierte können hier eine vollständige Erklärung des PageRank-Algorithmus lesen.
1 Russell, D., What Do You Need to Know to Use a Search Engine? Why We Still Need to Teach Research Skills, AI Magazine, 36(4), 2015.
2 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, 2015.
3 Spencer, S., Google Power Search: The Essential Guide to Finding Anything Online With Google, Koshkonong, Kindle Edition.
