29
Maschinenlernen geht in die Tiefe
Das menschliche Wissen ist breit gefächert und variabel, und es ist von Natur aus schwer zu erfassen. Der menschliche Verstand kann Wissen aufnehmen und damit arbeiten, weil er, wie Chomsky es ausdrückte, „ein überraschend effizientes und sogar elegantes System ist, das mit kleinen Informationsmengen arbeitet; es versucht nicht, grobe Korrelationen zwischen Datenpunkten zu erkennen, sondern Erklärungen zu finden1.“
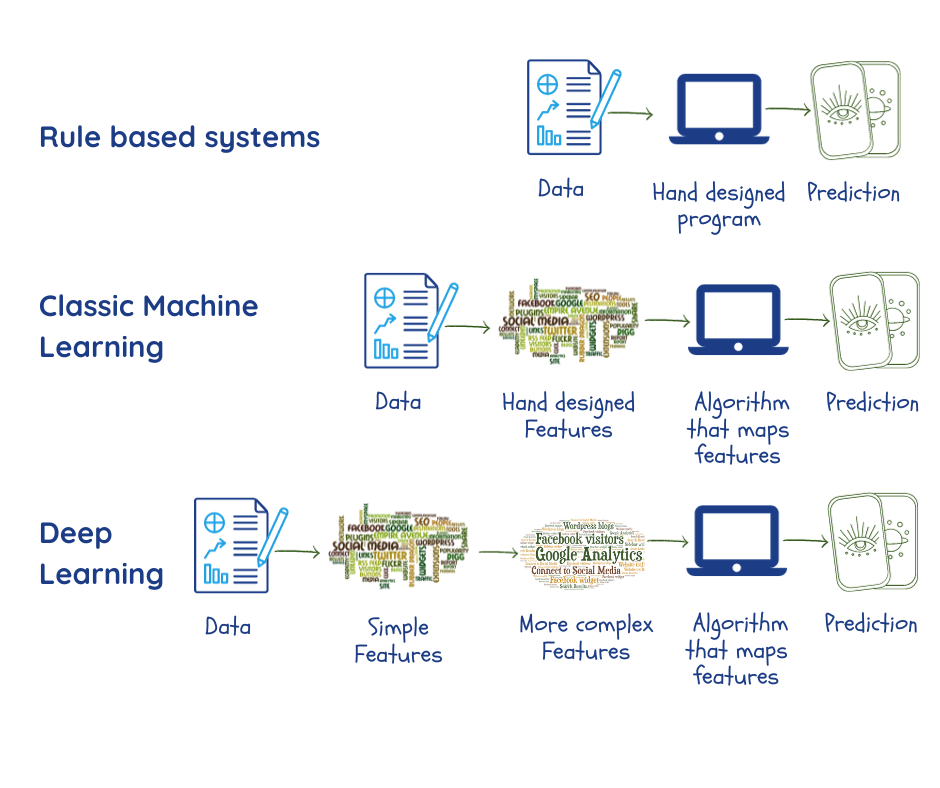
Maschinelle Lernen soll jedoch Muster in großen Datenmengen finden. Zuvor müssen sich jedoch Expertinnen und Experten und Programmierende programmieren, welche Datenmerkmale für das jeweilige Problem relevant sind und diese als „Parameter“ an die Maschine weitergeben2,3. Wie wir bereits gesehen haben, hängt die Leistung des Systems in hohem Maße von der Qualität dieser Daten und Parameter ab, die nicht immer leicht zu bestimmen sind.
Tiefe neuronale Netzwerke oder Deep Learning sind ein Teilbereich des maschinellen Lernens, der darauf abzielt, dieses Problem zu lösen, indem er während der Trainingsphase eigene Parameter aus den Daten extrahiert. Dabei werden mehrere Schichten verwendet, die Beziehungen zwischen den Parametern herstellen und dabei schrittweise von einfachen Darstellungen in der äußersten Schicht zu komplexeren und abstrakteren übergehen. Dadurch können gegenüber herkömmlichen ML-Algorithmen einige Dinge verbessert werden2.
Die meisten der leistungsstarken ML-Anwendungen verwenden Deep Learning. Dazu gehören Suchmaschinen, Empfehlungssysteme, Sprachtranskription und Übersetzung, die wir in diesem Buch behandelt haben. Es ist nicht übertrieben zu sagen, dass Deep Learning den Erfolg der künstlichen Intelligenz bei zahlreichen Aufgaben vorangetrieben hat.
„Tief” bezieht sich darauf, dass sich Schichten übereinander stapeln, um das Netzwerk zu bilden. Der Begriff „neural” spiegelt die Tatsache wider, dass einige Aspekte vom biologischen Gehirn inspiriert wurden. Auch wenn sie Einblicke in unsere eigenen Denkprozesse gewähren, handelt es sich doch um rein mathematische Modelle, die keinerlei biologischen Strukturen oder Prozessen ähneln2.
Die Grundlagen von Deep Learning
Wenn wir Menschen uns ein Bild ansehen, erkennen wir automatisch Objekte und Gesichter. Aber für einen Algorithmus ist ein Foto nur eine Ansammlung von Pixeln. Der Sprung von einem Durcheinander von Farben und Helligkeitsstufen zur Erkennung eines Gesichts ist zu kompliziert, um ihn durchzuführen.
Deep Learning erreicht dies, indem es den Prozess in der ersten Ebene in sehr einfache Darstellungen zerlegt – indem es beispielsweise die Helligkeitsstufe der benachbarten Pixel vergleicht, um das Vorhandensein oder Fehlen von Kanten in verschiedenen Regionen des Bildes festzustellen. In der zweiten Ebene werden Sammlungen von Kanten verwendet, um nach komplexeren Objekten zu suchen – wie Ecken und Konturen, wobei kleine Variationen der Kantenpositionen ignoriert werden2,3. Die darauffolgende Ebene sucht anhand der Konturen und Ecken nach Objektteilen. Langsam steigert sich die Komplexität, bis zu dem Punkt, an dem die letzte Ebene verschiedene Teile gut genug kombiniert, um ein Gesicht zu erkennen oder ein Objekt zu identifizieren.
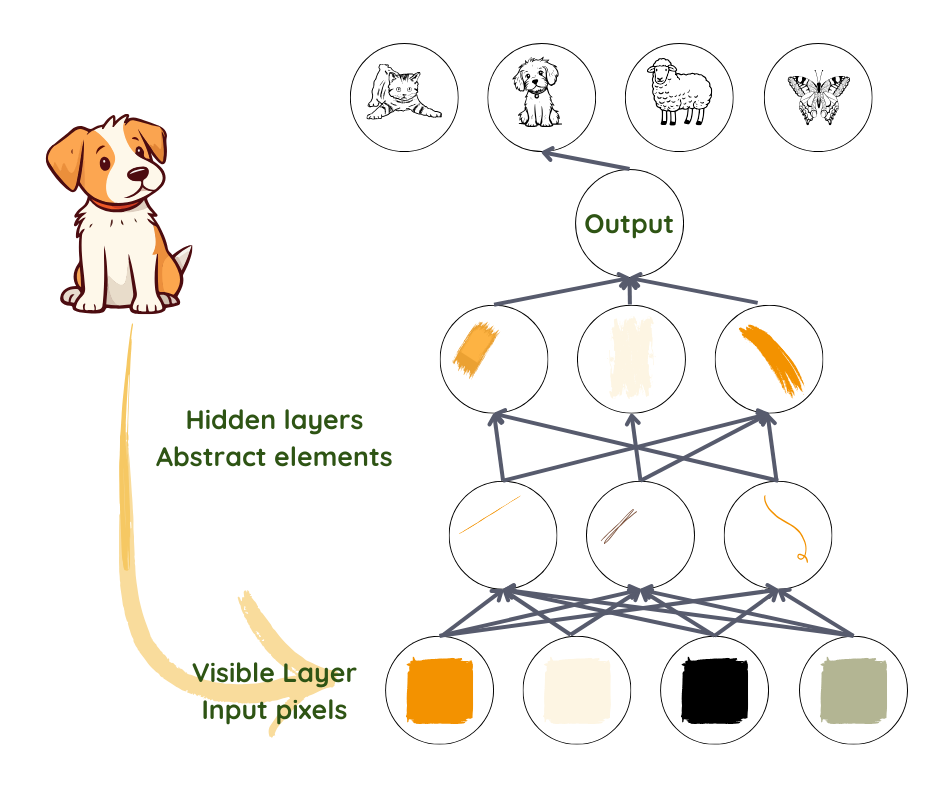
Was in den einzelnen Ebenen zu berücksichtigen ist, wird nicht von den Programmierenden festgelegt, sondern im Trainingsprozess aus den Daten gelernt3. Durch den Vergleich dieser Vorhersagen mit den tatsächlichen Ergebnissen des Trainingsdatensatzes wird die Funktionsweise jeder Ebene leicht verändert, um jedes Mal ein etwas besseres Ergebnis zu erzielen. Wenn alles korrekt funktioniert hat und ausreichend Daten von guter Qualität vorhanden sind, sollte sich das Netzwerk so entwickeln, dass es irrelevante Teile des Fotos, wie die genaue Position der Einheiten, den Winkel und die Beleuchtung, ignoriert und sich auf die Teile konzentriert, die die Erkennung ermöglichen.
Es ist zu beachten, dass trotz der Verwendung von Kanten und Umrissen zum Verständnis des Prozesses die Ebenen tatsächlich aus einer Reihe von Zahlen bestehen, die manchmal Dingen entsprechen können, die wir verstehen oder auch nicht. Was sich nicht ändert, ist der zunehmende Grad an Abstraktion und Komplexität.
Das Netzwerk gestalten
Sobald der Programmierende beschließt, Deep Learning für eine Aufgabe zu verwenden und die Daten vorbereitet hat, muss er oder sie die sogenannte Architektur seines neuronalen Netzwerkes entwerfen. Sie müssen die Anzahl der Ebenen (Tiefe des Netzwerkes) und die Anzahl der Parameter pro Ebene (Breite des Netzwerkes) bestimmen. Als Nächstes müssen sie entscheiden, wie die Verbindungen zwischen den Ebenen hergestellt werden sollen – ob jede Einheit einer Ebene mit jeder Einheit der vorherigen Ebene verbunden werden soll oder nicht.
Die ideale Architektur für eine bestimmte Aufgabe wird oft durch Experimente ermittelt. Je größer die Anzahl der Ebenen ist, desto weniger Parameter werden pro Ebene benötigt, das Netzwerk funktioniert darüber hinaus besser mit allgemeinen Daten, ist allerdings dann schwieriger zu optimieren. Weniger Verbindungen würden weniger Parameter und einen geringeren Rechenaufwand bedeuten, die Flexibilität des Netzwerks jedoch verringern2.
Das Netzwerk trainieren
Nehmen wir das Beispiel eines neuronalen Feedforward-Netzwerks, das überwachtes Lernen betreibt. Hier fließen die Informationen ohne Feedback-Schleifen von Ebene zu Ebene. Wie bei allen Techniken des maschinellen Lernens besteht das Ziel hier darin, herauszufinden, wie der Input mit dem Output zusammenhängt – welche Parameter zusammenkommen und wie sie zusammenkommen, um das festgestellte Ergebnis zu erhalten: Wir gehen von einer Beziehung f aus, die den Input x mit dem Output y verbindet. Dann verwenden wir das Netzwerk, um den Parametersatz θ zu finden, der die beste Übereinstimmung zwischen dem vorhergesagten und tatsächlichen Ergebnis ergibt.
Schlüsselfrage: Das vorhergesagte y ist f (x, θ), für welches θ?
Hier ist die Vorhersage für y das Endprodukt und Datensatz x als Input. Bei der Gesichtserkennung ist x normalerweise die Menge der Pixel in einem Bild, y kann der Name der Person sein. Im Netzwerk sind die Ebenen wie Arbeitende an einem Fließband, wo jeder Arbeitende das bearbeitet, was sie oder er erhält und es an den nächsten Arbeitenden weitergibt. Die erste nimmt den Input auf, wandelt ihn ein wenig um und gibt ihn an den zweiten in der Reihe weiter. Der zweite tut dasselbe, bevor er es an den dritten weitergibt, und so weiter, bis der Input schließlich in das Endprodukt umgewandelt ist.
Mathematisch gesehen wird die Funktion f in viele Funktionen f1, f2, f3… aufgeteilt, wobei f= ….f3(f2(f1(x))). Die Ebene direkt nach dem Input transformiert die Eingabeparameter mit f1, die nächste Ebene mit f2 und so weiter. Der Programmierende kann bei der Auswahl der richtigen Funktionsfamilie auf der Grundlage seines Wissens über das Problem eingreifen.
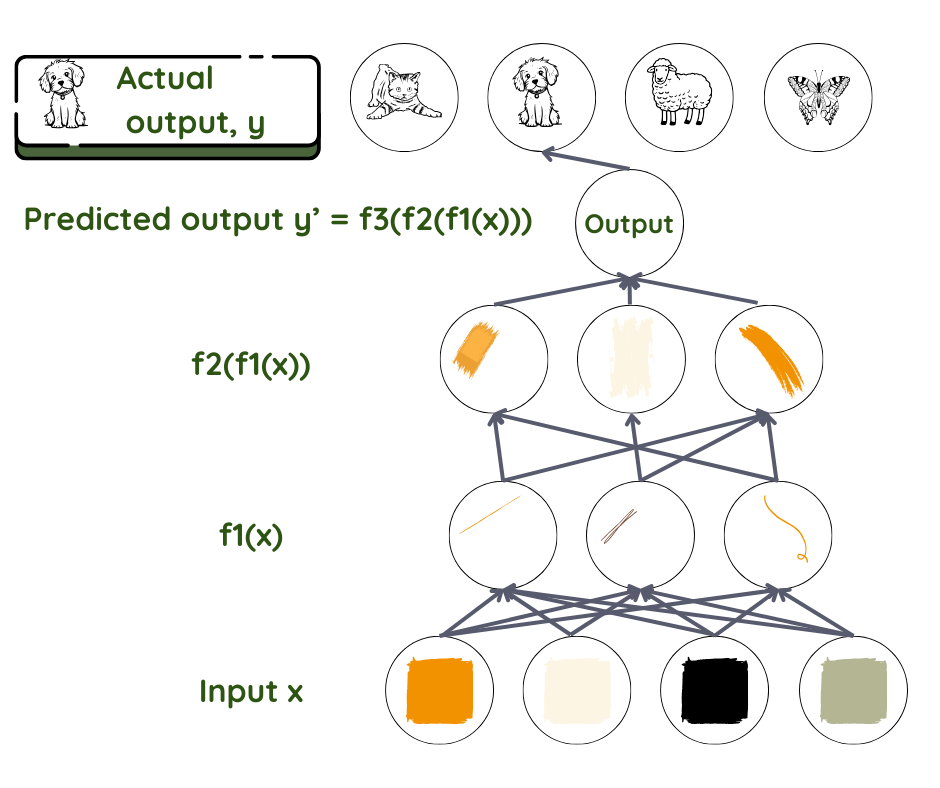
Jede Ebene hat die Aufgabe, jedem Parameter, den sie erhält, eine Bedeutung zuzuweisen – das ist die Gewichtung. Diese Gewichtungen sind wie Drehknöpfe oder Regler, die letztendlich die Beziehung zwischen dem vorhergesagten Output und dem Input in dieser Schicht definieren3. In einem typischen Deep-Learning-System haben wir es mit Hunderten von Millionen dieser Regler und Hunderten von Millionen von Trainingsbeispielen zu tun. Da wir den Output und die Gewichtung in den Ebenen zwischen Input und Output weder definieren noch sehen können, werden diese als versteckte Ebenen bezeichnet.
Im Falle des oben beschriebenen Beispiels der Objekterkennung ist es die Aufgabe des ersten Arbeiters, Kanten zu erkennen und diese an den zweiten weiterzugeben, der die Konturen erkennt usw.
Während des Trainings wird der vorhergesagte Output mit dem tatsächlichen Output verglichen. Wenn ein großer Unterschied zwischen beiden vorhanden ist, müssen die jeder Ebene zugewiesenen Gewichtungen stark verändert werden. Wenn nicht, müssen sie nur ein wenig geändert werden. Diese Arbeit wird in zwei Teilen durchgeführt. Zunächst wird die Differenz zwischen Vorhersage und Output berechnet, und dann berechnet ein anderer Algorithmus, wie die Gewichtungen in jeder Ebene geändert werden muss. Dabei wird mit der Output-Ebene begonnen (in diesem Fall fließen die Informationen aus den tieferen Schichten zurück). Am Ende des Trainingsprozesses ist das Netzwerk also mit seinen Gewichtungen und Funktionen bereit, Testdaten zu verarbeiten. Der Rest des Prozesses ist derselbe wie beim herkömmlichen maschinellen Lernen.
1 Chomsky, N., Roberts, I., Watumull, J., Noam Chomsky: The False Promise of ChatGPT, The New York Times, 2023.
2 Goodfellow, I.J., Bengio, Y., Courville, A., Deep Learning, MIT Press, 2016.
3 LeCun, Y., Bengio, Y., Hinton, G., Deep learning, Nature 521, 436–444 (2015).
